Bölüm 7
Eşit Yüzdelikli Eşitleme
Bu kısımda eşit yüzdelikli eşitleme, eşitleme desenlerine göre açıklanmıştır. Eşit yüzdelikli eşitlemenin tanıtımı ve genel özelliklerine random grup, tek grup ve dengelenmiş tek grup deseni başlığı altında yer verilmiştir.
Random Grup, Tek Grup ve Dengelenmiş Tek Grup Deseni
Eşit yüzdelikli eşitleme, ortalama eşitleme ve doğrusal eşitlemeye göre daha az varsayımları olan ve daha karmaşık bir süreçtir. Ortalama eşitleme X ve Y testlerinin sadece ortalamalarının arasında fark olduğunu; doğrusal eşitleme X ve Y testlerinin ortalama ve standart sapmaları arasında fark olduğunu ve dağılımın diğer parametrelerinin eşit olduğunu kabul eder. Eşit yüzdelikli eşitleme, X ve Y formlarının ortalaması ve standart sapmasının yanı sıra çarpıklık ve basıklık parametreleri farklı olduğunda da kullanılabilir. Yani formların dağılımına ilişkin bir sınırlama yoktur ancak dağılımlara ilişkin esneklik sağlaması yöntemin daha karmaşık olmasına ve diğer iki eşitleme yöntemine göre daha büyük örneklem gerektirmesine neden olur. Yeterince büyük örneklem sağlandığında ise puan dağılımları farklı olsa da ortalama ve doğrusal eşitlemeden daha doğru sonuçlar elde edilebilir (Finch & French 2018; Kolen & Brennan, 2014).
Eşit yüzdelikli eşitleme, X ve Y formlarındaki puanların yüzdelik sıralarının bulunarak aynı yüzdelik sıradaki puanların eşitlenmesidir. Örneğin, X formundaki 60 puanın yüzdelik sırası 75 ise 60 puanın Y formundaki eşit yüzdelikli karşılığının bulunması için Y’deki 75. yüzdeliğe karşılık gelen puanı araştırırız. Y formunda 75. yüzdeliğe 65 puan karşılık geliyorsa X formundaki 60 puanın Y formundaki 65 puana eşit olduğunu ifade ederiz. Eşit yüzdelikli eşitleme hem grafik yöntemle hem de analitik olarak yapılabilir.
Eşit yüzdelikli eşitleme fonksiyonu Y formundaki puanlarla aynı yüzdelik sırasına sahip olan X formundaki puanları belirler. Eşit yüzdelikli eşitleme sonucunda X’in Y formuna eşitlenmiş puan dağılımı ile Y formunun puan dağılımı aynı olur.
Eşit yüzdelikli eşitleme sonucunda, X formunun Y formuna dönüştürülmüş puanlarının yığmalı dağılımı, Y formunun yığmalı dağılımına eşit olur. Braun ve Holland (1982) tarafından geliştirilen eşit yüzdelikli eşitleme yönteminde, X ve Y sürekli ve random değişken olmak üzere, eşitleme fonksiyonu aşağıdaki gibi tanımlanmıştır:
\[e_y (x)=G^{-1} [F(x)] \quad (7.1)\]
F: X’in evrendeki yığmalı yüzde dağılımı
G: Y’nin X ile aynı evrende olan yığmalı yüzde dağılımı
\(G^{-1}\): G yığmalı dağılımının ters fonksiyonu
\(e_y\)’nin eşitleme fonksiyonu olması için simetrik olması gerekir.Y formunun puanları X’e dönüştürüldüğünde aynı değerler elde edilir.
\[e_x (y)=F^{-1} [G(x)] \quad(7.2)\] \(F^{-1}\): F yığmalı dağılımının ters fonksiyonu
Eşit yüzdelikli eşitlemede her iki formda aynı yüzdelik sıradaki puanları belirleme süreci, test puanlarının sürekli bir random değişken olduğu varsayımına dayanır ancak test puanları kesiklidir, tam sayı değerleri alır. Bu nedenle X formundaki her yüzdelik sıraya Y formunda karşılık gelen bir puan bulunmayabilir. Holland ve Thayer (1989), kesikli puanlar için süreklileştirme ve Kernel düzgünleştirme adını verdikleri bir süreci kullanmışlardır. X kesikli ve tam sayı değerler alan bir random değişken, U (-0,5;+0,5) arasında değerler alan bir random değişken olmak üzere bir X*=X+U değişkeni tanımlamışlardır (Kolen & Brennan, 2014). Analitik yöntemde test puanları U ile genişletilerek eşitleme yapılmaktadır.
Grafik Yöntem
Grafik yöntemle eşit yüzdelikli eşitleme yapmak için ilk önce puanların yüzdelik sıraları elde edilmelidir.
\[P(x)=100{F(x-1)+\frac {f(x)}{2}}\quad(7.3)\] \(P(x)\): x puanının yüzdelik sırası
\(f(x)\): x puanını alanların sınava girenlere oranı
\(F(x)\): x puanı ya da o puana kadar olan bireylerin yığmalı oranı
Tablo 7.1’de örnek olarak beşer maddelik X ve Y formlarından alınan puanların frekans, yüzde ve yüzdelik sıraları verilmiştir.

X formundaki x=2 puanının yüzdelik sırasını bulalım.
\(P(2)= 100*{(0,3)+\frac{0,3}{2}}\)
\(P(2)= 100*(0,3+0,15)\)
\(P(2)=45\)
Y formundaki y=0 puanının yüzdelik sırası
\(P(0)=100*{0+\frac{0,2}{2}}\)
\(P(0)=100*(0+0,1)\)
\(P(0)=10\) bulunur.
Tablo 3 incelendiğinde X forumundaki 5 puan, Y formundaki 5 puanla aynı yüzdelik sıradadır. Y formunda 0, 1, 2, 3 ve 4 puanlarının X formundaki yüzdelik sıralarına karşılık gelen puan yoktur. X formundaki puanları Y formuna eşitlemek için Şekil 7.1’deki gibi bir grafik çizilir. Yüzdelik hesaplamasında puanların (-0,5;+0,5) aralığında genişletilmesinden dolayı grafikte de yatay eksendeki puanlar bu aralıkta genişletilmiştir.
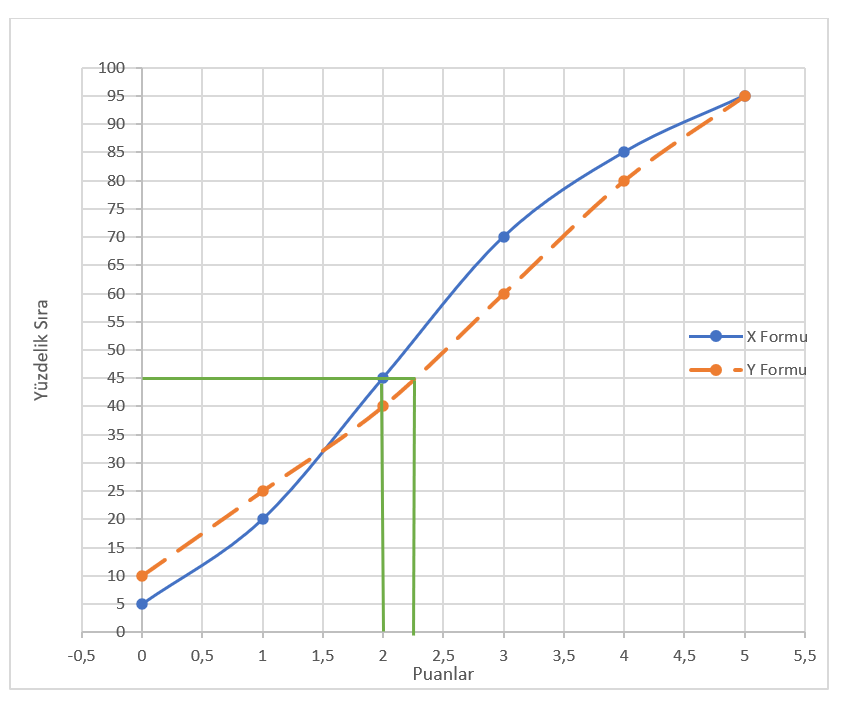
Şekil 7.1’de puanlar yatay eksende, yüzdelik sıra düşey eksende yer almaktadır. Grafikten yararlanarak X formundaki bir puanla aynı yüzdelik sıraya karşılık gelen Y puanı kestirilir. X formundaki 2 puanın yüzdelik sırasının 45 olduğu grafikten görülmektedir. Y formunda 45. yüzdelik sıraya karşılık gelen puan da grafikten kestirilir. Y formundaki 45. yüzdelik sıraya karşılık gelen puanın yaklaşık 2,25 olduğu görülmektedir. Y formundaki tüm puanlar bu şekilde X formuna eşitlenir.
Grafik yöntemle bu şekilde puanların eş değerlerinin bulunması hatalı olabilir. Puan ranjı genişledikçe kestirimlerde hata artar.
Analitik Yöntem
Analitik yöntemler, grafik yönteme göre karmaşık olsa da daha doğru sonuçlar sağlamaktadır. Analitik yöntemde ilk aşamada X formundaki puanların yüzdelik sıraları bulunur.
X formunun test puanları, K testteki madde sayısını göstermek üzere, 0 ile K arasında değişen tam sayılardır. Test puanları tam sayı olmadığında x’e en yakın tam sayıyı gösteren \(x^*\) tanımlanır \((x^* -0,5 ≤ x < x^*+0,5)\). Örneğin \(x=2,7\) için \(x^*=3\); \(x=2,2\) için \(x^*=2\) ve \(x=2,5\) için \(x^*=2\) olur.
Puanlar tam sayı olmadığında ya da (-0,5;+0,5) aralığında genişletildiğinde yüzdelik sırası Eşitlik (7.4) ile hesaplanabilir.
\[P(x)=100{F(x^*-1)+[x-(x^*-0,5)][F(x^*)-F(x^*-1)]} \quad (7.4)\]
\(P(x)\): x puanının yüzdelik sırası
\(x^*\): x’e en yakın tam sayı
\(F(x)\): Kesikli değişkenin yığmalı dağılım fonksiyonu. Bir x puanı ya da o puana kadar olanların oranıdır.
X formunun puanları \(-0,5 ≤ x < K+0,5\) arasındadır. \(x<0\) olduğunda \(P(x)=0\), \(x≥K+0,5\) olduğunda \(P(x)=100\) olur. Eşitlik (7.4)’te puanlar tam sayı olduğunda \(x\) ve \(x^*\) birbirine eşit olur. Ancak \(x\) tam sayı olmadığında \(x^*\) ve \(x\) farklılaşır. Örneğin \(x=3,2\) için \(x^*=3\) olur.
Tablo 7.1’de verilen 5 maddelik testte açık uçlu bir madde olduğunu ve tam sayı olmayan puanlar da alınabildiğini düşünelim. Bu testten alınan \(x=3,2\) puanın yüzdelik sırasını hesaplayalım:
\(x^*\)=3
\(P(3,2)=100(F(2)+(3,2-(3-0,5)(F(3)-F(2))\)
\(P(3,2)=100{0,6+(3,2-2,5)(0,8-0,6)}\)
\(P(3,2)=100(0,6+0,7*0,2)\)
\(P(3,2)=74\) olur.
Yüzdelik sıra fonksiyonun tersi \(P^{-1}\) olarak gösterilmiştir. Bu fonksiyon ile belirli bir yüzdelik sıraya karşılık gelen puan bulunur.
\[P^{-1} (P^*)=\frac{P^*/100-F(x_U^*-1)}{F(x_U^*)-F(x_U^*-1)}+(x_U^*-0,5)\quad (7.5)\] \(0≤P^*<100\)
\[P^{-1} (P^*)=\frac{P^*/100-F(x_L^*))}{(F(x_L^*+1)-F(x_L^*))}+(x_L^*+0,5)\quad (7.6)\] \(0<P^*≤100\)
\(P^{-1} (P^*)\): Belli bir yüzdelik sıraya karşılık gelen puanı bulan yüzdelik fonksiyon
\(x_U^*\): \(P^*\)dan daha büyük bir yığmalı yüzdeye karşılık gelen en küçük tam puan
\(x_L^*\): \(P^*\)dan daha küçük bir yığmalı yüzdeye karşılık gelen en büyük tam puan
Bir yüzdelik sıraya karşılık gelen puan Eşitlik (7.5) ve (7.6)’dan herhangi biriyle hesaplanabilir. Eşitlik (7.5) ve (7.6), dağılımda herhangi bir puanın yüzdesi (\((f_x)\)) sıfır olmadıkça aynı sonuçları verir. Eğer dağılımda bir puanın yüzdesi sıfır olursa iki değer eşit çıkmaz, bu durumda \(x=(x_U+x_L)/2\) kullanılır.
X formundaki bir puanın yüzdelik sırasının Y formunda hangi puana karşılık geldiği Eşitlik (7.7)’deki eşitleme fonksiyonu ile bulunur.
\[e_y(x)=Q^{-1}[P(x)] \quad (7.7)\] x puanları tam sayıdır ve 0 ile toplam doğru sayısı arasında değişir.
Eşitlik (7.7) simetriktir. Y formundaki bir puanın X’deki eşdeğerini bulmak için de düzenlenebilir.
\[e_x(y)=P^{-1}[Q(y)] \quad (7.8)\] \(Q(y)\): y puanının yüzdelik sırası
\(Q^{-1}\): Y formundaki yüzdelik sıra fonksiyonunun tersi
\(P(x)\): x puanının yüzdelik sırası
\(P^{-1}\): X formundaki yüzdelik sıra fonksiyonunun tersi
Eşitlik (7.7) ve (7.8) aslında yüzdelik bulan fonksiyonlardır. Eşitlik (7.6)’yı Y formu için düzenleyip Eşitlik (7.8)’de yerine koyarsak eşitleme fonksiyonu Eşitlik (7.9) gibi olur.
\[e_y(x)=\frac{P^*/100-G(y_U^*-1)}{G(y_U^*)-G(y_U^*-1)}+(y_U^*-0,5)\quad (7.9)\]
Tablo 7.1’de, X formundaki 2 puanının Y’deki karşılığını bulalım. Bunun için x=2’nin yüzdelik sırasına bakmamız gerekir. Tablo 7.1’de bu değerin \(P^*\)= 45 olduğu görülür. Y formunda 0,45 yüzdelikten (45/100) daha büyük yığmalı yüzde 0,5’dir ve bu da 2 puana karşılık gelmektedir. Bu durumda, \(y_U^*\)=2 ve \(G(y_u^*-1)\)’e karşılık gelen değer de 0,3’tür. Bu değerler Eşitlik (7.9)’da yerine koyularak X formundaki 2 puanının Y’deki karşılığı bulunur.
\[e_y(x)=\frac{45/100-0,3}{0,5-0,3}+(2-0,5)\] \[e_y(x)=2,25\]
Tablo 7.1’de X formundaki 5 puanının Y’deki karşılığını bulalım. Bunun için x=5’in yüzdelik sırasına bakmamız gerekir. \(P^*\)= 95. Y formunda 5 puanın yüzdelik sırası da 95 olduğundan X’deki 5 puanın karşılığı Y’de de 5 puandır. Formülde değerleri yerine koyduğumuzda da aynı sonucu elde ederiz. Y formunda (95/100) 0,95’den daha büyük yığmalı yüzde 1’dir ve 5 puana karşılık gelmektedir. Bu durumda, \(y_U^*\)=5’dir.
\[e_y(x)=\frac{95/100-0,9}{1-0,9}+(5-0,5)\] \[e_y(x)=5\]
Tablo 7.2’de X formunun Y’ye eşitlenmiş puanları [\(e_y(x)\)] yer almaktadır.
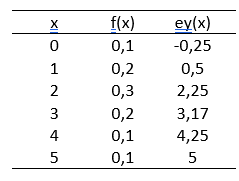
Eşitlenmiş puanlar -0,25 ila 5 arasında değişmektedir. Eşit yüzdelikli eşitlemede eşitlenmiş puanların ranjı -0,5 ila K+0,5 arasında değişir.
Puan Dağılımının Düzgünleştirilmesi
Eşit yüzdelikli eşitlemede, puan dağılımında her yüzdelik puana karşılık bir puan gelmemesi sıklıkla karşılaşılan bir durumdur. Örneklem küçük olduğunda bu durumla daha fazla karşılaşılır ve puan dağılımında düzensizlikler görülür. Bu da eşitlemede hataya yol açabilir. Puan dağılımındaki bu düzensizlikleri ortadan kaldırmak için düzgünleştirme (smoothing) yapılır. Örneklemdeki dağılımların evren dağılımında olduğu gibi düzgün hale getirilmesi ve eşitlenmesi için düzgünleştirme yöntemleri geliştirilmiştir. Düzgünleştirilmiş puan dağılımlarıyla yapılan eşitlemenin daha az hatalı olması beklenir ancak bu beklenti her zaman gerçekleşmeyebilir. Özellikle puan sayısı az olduğunda ve puanlar arasındaki ayrıklıklar fazla olduğunda düzgünleştirme sonucunda yapılan eşitlemeler de hatalı sonuç verebilmektedir (Kolen & Brennan, 2014).
Düzgünleştirme iki türlü yapılabilir. Ön düzgünleştirmede, eşitleme yapmadan önce puan dağılımı düzgünleştirilir. Son düzgünleştirmede ise eşitlenmiş puanlar düzgünleştirilir. Düzgünleştirmede kullanılan yöntemler aşağıdaki dört özelliğe sahip olmalıdır:
Düzgünleştirme yöntemi, evren dağılımlarını veya eşitlenmiş puanları doğru tahmin etmelidir. Bu da, düzgünleştirme ile elde edilen eşitleme sonuçlarının sistematik hata içermemesi anlamını taşır.
Düzgünleştirme yöntemi, uygulamada karşılaşılabilecek çeşitli puan dağılımlarını ve eşit yüzdelikli ilişkileri içerecek esneklikte olmalıdır.
Düzgünleştirme yönteminin, yöntemin uyumunu değerlendirebilmek için istatistiksel bir çerçevesi olmalıdır.
Düzgünleştirme yöntemi, eşitlemenin yaptığı tahminleri daha da iyileştirmelidir.
Kolen & Brennan (2014), random gruplarda eşit yüzdelikli eşitlemede log-doğrusal ön düzgünleştirme ve kübik spline son düzgünleştirme yöntemleri üzerinde kapsamlı araştırmalar yapıldığını ve araştırmalarda bu yöntemlerin eşitleme tahminlerini iyileştirdiğini belirtmiştir. Bu iki yöntem kısaca açıklanmıştır.
Log-doğrusal Ön Düzgünleştirme
Log-doğrusal modeller sıralama özelliği taşıyan çok terimli (poly-nominal) puan dağılımlarını tahmin etmek için uygulanabilir (Kolen & Brennan, 2014). Holland ve Thayer (2000), bu modellerin puan düzgünleştirmede kullanımını da içeren kapsamlı bir tanıtımını yapmışlardır. Log-doğrusal model, test puanlarının polinom fonksiyonu cinsinden beklenen oranlarını ifade eder ve bu model Eşitlik (7.10) ile test formlarındaki ham puanları düzgünleştirir (Finch & French, 2018; Moses, 2011).
\[\ln(P_j) = \alpha + \beta_1 x_j + \beta_2 x_j^2 + \cdots + \beta_C x_j^C\quad (7.10)\]
\(x_j\): j. test puanı
\(P_j\): j. test puanının olasılığı
\(C\): Modele uyum sağlayan en yüksek sıralı terimin derecesi
\(β_C\): \(C\) teriminin katsayısı
\(β_C\) katsayısı en çok olabilirlik kestirimi ile elde edilebilir. \(C\) değeri, ham puan dağılımı ve düzeltilmiş puan dağılımının eş değer olan momentlerini belirler. Bu nedenle \(C\)’nin seçimi çok önemlidir. Örneğin, \(C\)=2 olduğunda ham puan ve düzgünleştirilmiş puan dağılımının ilk iki momenti (ortalama ve standart sapma) eşit olacaktır. Bu durumda model denklemi \(\ln(P_j) = \alpha + \beta_1 x_j + \beta_2 x_j^2\) olur. \(C\)=4 seçildiğinde ham puanların ve düzgünleştirilmiş puanların ortalaması, standart sapması, çarpıklığı ve basıklığı aynı olacaktır.
Farklı \(C\) değerleri için yapılan düzgünleştirilmiş puanların dağılımının grafiğiyle ham puan dağılımının \(C\) grafiği karşılaştırılarak en uygun \(C\) değerini içeren denkleme göre düzgünleştirme yapılabilir. Puan düzgünleştirmesi için en uygun \(C\) değeri olabilirlik oranı testi sonucuna göre de seçilebilir (Kolen & Brennan, 2014). Olabilirlik oranı testinde her \(C\) değerinin anlamlılığı, \(C-1\) serbestlik derecesinde \(\chi^2\) ile test edilir. Modeller iç içe geçtiğinden ardışık iki \(C\) değerinin \(\chi^2\) istatistiği arasındaki fark bulunarak manidarlık testi yapılır. Örneğin \(C\)=2 ve \(C\)=3 değerleri ile kurulan modeller için (\(\chi_{C=2}^2-\chi_{C=3}^2\)) arasındaki fark 1 serbestlik derecesi ile test edilir. Farkın manidar çıkması daha büyük \(C\) değerine sahip modelin ( \(C\)=3) verilere daha iyi uyum sağladığını gösterir. Fark manidar çıkmadığında, \(C\) değeri daha küçük olan model ( \(C\)=2) veriye daha iyi uyum göstermektedir. Model seçimi için Akaike bilgi fonksiyonu ( \(AIC\) ) da kullanılabilir (Kolen & Brennan, 2014). \(AIC\), genel ki-kare istatistiğine dayanır ve \(AIC=\)\(\chi_{C}^2+2(C+1)\) olarak hesaplanır. Bu istatistik, her \(C\) değeri için ayrı ayrı hesaplanır. En küçük AIC değerine sahip olan \(C\) en iyi model olarak seçilir.
Model seçiminde uyum istatistikleri, puan dağılımı grafikleriyle birlikte değerlendirilmelidir. Grafikler incelenirken seçilen düzgünleştirme dağılımının düzgün olup olmadığına ve ham puan dağılımından çok fazla sapma gösterip göstermediğine de bakılmalıdır.
Kübik Spline Son Düzgünleştirme
Son düzgünleştirme, test formları eşitlendikten sonra yapılır ve \(e_y(x)\) puanları düzgünleştirilir. Son düzgünleştirme yöntemleri, eşit yüzdelikli ilişkiye bir eğri uydurur. Gözlenen ilişkiden çok fazla sapmadan düzeltilmiş ilişkinin düzgün görünmesi gerekir. Kübik spline yöntemi esnekliği fazla olması nedeniyle alan yazında en fazla kullanılan son düzgünleştirme yöntemidir. Bir tam sayı olan \(x_i\) puanı için spline fonksiyonu Eşitlik (7.11) ile tanımlanır.
\[d_y(x) = \nu_{0i} + \nu_{1i}(x - x_i) + \nu_{2i}(x - x_i)^2 + \nu_{3i}(x - x_i)^3\quad (7.11)\] \(x_i≤x≤x_i+1\)
\(υ\) ile gösterilen ağırlıklar bir puan noktasından diğerine değişir. Böylece her tam sayı puan için farklı bir kübik denklem tanımlanmış olur. Her puan noktasında (\(x_i\)) kübik spline süreklidir ve dağılımdaki en düşük tam sayı puan ile en yüksek tam sayı puan aralığındadır. Puan noktaları arasındaki eğriliği en aza indirmek için Eşitlik (7.12) uygulanır.
\[\frac{\sum_{i=low}^{high}[(d_y(x_i) - e_y(x_i))/se[e_y(x_i)]]^2}{(x_{high} - x_{low})} \leq S\quad (7.12)\] Eşitlik (7.12)’de düşük puanlardan yüksek puanlara doğru olan toplam, spline’ın uyum gösterdiği noktalar üzerinden yapılır. \(se[e_y (xi)], e_y (xi)\)’nin standart hatasıdır. Eşitlemenin standart hatası, düzgünleştirilmemiş ve düzgünleştirilmiş puanlar arasındaki farkları standartlaştırmak için kullanılır. Standart hatanın küçük olması, düzgünleştirilmemiş ve düzgünleştirilmiş ilişkilerin daha yakın olmasına neden olur, standart hata büyük olduğunda puanlar arasındaki ilişkiler uzaklaşır. \(S\) parametresi ($S ≥ 0$) araştırmacı tarafından ayarlanır ve düzgünleştirmenin derecesini kontrol eder. Düzgünleştirme sürecinde araştırmacı tarafından \(S\)’nin çeşitli değerleri denenir ve sonuçları karşılaştırılır. Eğer \(S = 0\) ise uyumlu olan spline tüm tam sayı puan noktalarındaki düzgünleştirilmemiş \(e_y(x)\) değerlerine eşittir. Eğer \(S\) çok büyükse spline fonksiyonunun grafiği düz bir çizgi olur. \(S\)’nin ara değerleri, düzgünleştirilmemiş eşit yüzdelikli ilişkiden değişen derecelerde sapan ve doğrusal olmayan bir fonksiyon üretir. Eğer \(S = 1\) ise düzgünleştirilmiş ve düzgünleştirilmemiş \(e_y(x)\) değerleri arasındaki standartlaştırılmış ortalamanın karesi arasındaki fark 1,0’dır. \(S\)’nin 0 ila 1 arasındaki değerlerinin pratikte yeterli sonuçlar verdiği görülmüştür (Kolen & Brennan, 2014).
Denk Olmayan Gruplarda Ortak Test Deseni
Denk olmayan gruplarda ortak test deseninde eşit yüzdelikli eşitleme yöntemleri, toplam puanların ve ortak madde puanlarının dağılımlarını dikkate alır. Ortak maddeler aracılığıyla X ve Y formlarının puan dağılımları eşitlenir. Bu bölümde denk olmayan gruplarda ortak test deseninde eşit yüzdelikli eşitleme için kullanılan frekans kestirimi ve zincirleme eşitleme yöntemleri tanıtılacaktır.
Frekans Kestirimi
Frekans kestirimi yöntemi ilk olarak Angoff (1971) tarafından tanıtılmıştır. Frekans kestirimi ile eşitleme, her iki grup tarafından alınan bir ortak test temelinde, sınava giren farklı gruplar tarafından alınan bir testin iki formundaki puanların eşitlenmesine yönelik bir yöntemdir. Ortak test, testin her iki formunda yer alan ortak maddelerden oluşabileceği gibi (iç ortak test), benzer yetenekleri ölçen ayrı bir test (dış ortak test) de olabilir (Livingston & Feryok, 1987).
Bu yöntemde denk olmayan gruplarda ortak test desenindeki doğrusal eşitlemede olduğu gibi X ve Y formları için sentetik bir evren oluşturulur ve bu evrende X ve Y formlarındaki puanların yığmalı dağılımları kestirilir. Puan dağılımları kestirildikten sonra random gruplarda eşit yüzdelikli eşitlemede kullanılan yöntemle eşitleme yapılır (Kolen & Brennan, 2014).
Frekans kestirimi yöntemi için koşullu dağılımlar kullanılır.
\[f(x|v) = \frac{f(x,v)}{h(v)}\quad (7.13)\] Eşitlik (7.13) \(f(x,v)\) için de yazılabilir.
\[f(x,v)= f(x│v) h(v)\quad (7.14)\]
\(f(x│v)\): V testinden alınan v puanının X formundan x puanı alma olasılığıdır.
\(f(x,v)\): Toplam puan ve ortak madde puanının birleşik dağılımıdır. X formundan x puanını, V formundan v puanını alma olasılığını gösterir.
\(h(v)\): V testinden v puanı alma olasılığıdır.
Denk olmayan gruplarda ortak test deseninde frekans kestirimiyle eşit yüzdelikli eşitleme yapabilmek için sentetik evrenlerin tanımlanması gerekir. \[f_s (x)=w_1 f_1 (x)+w_2 f_2 (x) \quad (7.15)\] \[f_s (y)=w_1 f_1 (y)+w_2 f_2 (y) \quad (7.16)\]Eşitlik (7.15) ve (7.16)’da s indisi sentetik evreni göstermektedir. X formunun uygulandığı grup 1, Y formunun uygulandığı grup, 2 indisiyle gösterilmiştir. w1 ve w2 grupların ağırlığını (w1+w2=1), f ve g sırasıyla X ve Y formunun puan dağılımını ifade etmektedir. X formu Grup2’ye, Y formu Grup1’e uygulanmadığı için Eşitlik (7.15) ve Eşitlik (7.16)’daki \(f_2 (x)\) ve \(f_1 (y)\) dağılımları elde edilemez. Ortak maddelerin X ve Y formlarıyla koşullu dağılımlarına ilişkin bir istatistiksel varsayımla toplanan verilerden bu dağılımlar kestirilir.
Frekans kestirimi yönteminde X ve Y formu için ortak testten alınan aynı puanın (V=v) koşullu dağılımının her iki evrende (Grup1 ve Grup2) eşit olduğu varsayımı yapılır.
\[f_1 (x│v)=f_2 (x│v)\quad (7.17)\] \[g_1 (x│v)=g_2 (x│v)\quad (7.18)\] Eşitlik (7.17) ve (7.18), \(f_2\) ve \(g_1\) için düzenlendiğinde Eşitlik (7.19) ve (7.20)’deki denklemler elde edilir.
\[f_2 (x,v)= f_2 (x│v) h_2 (v) \quad(7.19)\] \[g_1 (y,v)= g_1 (y│v) h_1 (v) \quad (7.20)\] Eşitlik (7.17) ve (7.19) birlikte ele alındığında Grup2 için \((x,v)\) birleşik dağılımı, Eşitlik (7.18) ve (7.20) birlikte ele alındığında Grup1 için \((y,v)\) birleşik dağılımı elde edilir.
\[f_2 (x,v)= f_1 (x│v) h_2 (v)\quad (7.21)\]
\[g_1 (y,v)= g_2 (y│v) h_1 (v) \quad (7.22)\]Eşitlik (7.21)’deki \(f_1 (x│v)\) X formunu alan Grup1’in puanlarından, \(h_2 (v)\) de Y formunun ortak testini alan Grup2’nin puanlarından elde edilir. Benzer şekilde Y formunu alan Grup2’nin puanlarından Eşitlik (7.22)’deki \(g_2 (y│v)\) ve X formunun ortak testini alan Grup1’in puanlarından \(h_1 (v)\) hesaplanabilir.
Y formunu alan grup için \(f_2 (x)\) ve X formunu alan grup için \(g_1 (y)\) dağılımları, birleşik dağılımların ortak maddeler üzerinden toplanmasıyla elde edilir.
\[f_2(x) = \sum_v f_2(x,v) = \sum_v f_1(x|v)h_2(v)\quad(7.23)\] \[g_1(y) = \sum_v g_1(y,v) = \sum_v g_2(y|v)h_1(v)\quad(7.24)\]
Eşitlik (7.23) ve (7.24)’teki tüm değişkenler gözlenen verilerden kestirilebilir. Böylece Eşitlik (7.17) ve (7.18)’deki sentetik evren parametresi tüm grup için elde edilir.
\[f_s(x) = w_1 f_1(x) + w_2 \sum_v f_1(x|v) h_2(v)\quad(7.25)\] \[g_s(y) = w_1 \sum_v g_2(y|v) h_1(v) + w_2 g_2(y)\quad(7.26)\] Grup2 için \(w2=0\) alınırsa Eşitlik (7.25) ve (7.26) aşağıdaki gibi sadeleştirilebilir.
\[f_s(x) = w_1 f_1(x)\]
\[g_s(y) = w_1 \sum_v g_2(y|v) h_1(v)\] Eşitlik (7.25) ve (7.26)’daki tüm değerler gözlenen verilerden doğrudan elde edilebilir. Sentetik evrende \(F(x)\) dağılımını elde etmek için \(f_s(x)\) değerlerinin, \(G(y)\) dağılımını elde etmek için \(g_s(y)\) değerlerinin yığmalı toplamları alınır. \(F(x)\) ve \(G(y)\) dağılımlarının yüzdelik sıraları Eşitlik (7.4) ile elde edilir. Sentetik evren için eşit yüzdelikli eşitleme denklemi Eşitlik (7.7)’ye benzerdir.
\[e_Ys (x)=Q_s^{-1} [P_s (x)] \quad (7.27)\]Frekans kestirimi ile eşit yüzdelikli eşitleme için izlenen adımlar aşağıdaki örnek veri üzerinden açıklanmıştır:
Eşitleme için X ve Y formlarında 10’ar madde ve 3 ortak maddesi olan testlerin, Grup1 ve Grup2’de 100’er kişiye uygulandığını düşünelim. Bu verilerin frekans kestirimi için izlenen adımlar şöyledir.
- X ve Y formlarının ortak madde puanları (v) ile çapraz frekans dağılımları elde edilir. Bu dağılımlar Tablo 7.3 ve Tablo 7.4’te verilmiştir.


Tablolarda X veya Y formundan belli bir puanı alan kişilerin ortak madde puanlarındaki dağılımı yer almaktadır. Satır toplamları ana formlardaki puanları alan kişilerin toplam sayısını, sütun toplamları da ortak maddelerdeki puanları alan kişilerin toplam sayısını gösterir. Örneğin X formundan 1 puan alan 2 kişi vardır, birisi ortak maddelerden hiçbirine doğru cevap verememiş, birisi de 1 tanesini cevaplandırmıştır. Y formundan 4 puan alan 6 kişi vardır. Bu 6 kişiden birisi ortak maddelerden 0 puan, ikisi 1 puan, ikisi 2 puan ve birisi de 3 puan almıştır.
- Tablo 7.3 ve Tablo 7.4’teki frekansların, satır ve sütun toplamlarının yüzdeleri alınır, toplam puanların yığmalı yüzdeleri hesaplanır. Tablo 7.5 ve 7.6’da bu değerler yer almaktadır.
![Tablo 7.5 X formundaki frekansların, satır ve sütun toplamlarının yüzdeleri [f_1(x,v)]](Sekil/Tablo8.PNG)
![Tablo 7.6 Y formundaki frekansların, satır ve sütun toplamlarının yüzdeleri [g_2(y,v)]](Sekil/Tablo9.PNG)
Tablo 7.5 ve 7.6‘daki frekansların yüzdeleri, Eşitlik (7.19) ve (7.20)’deki bileşik yüzdeleri \([f_1 (x,v)\) ve \(g_2 (y,v)]\); sütun toplamları da ortak maddeler toplam frekanslarının yüzdelerini gösterir \([h1(v)\) ve \(h2(v)]\). \(F(x)\) ve \(G(y)\) sütunları puanların yığmalı yüzdeleridir.
- Eşitlik (7.17) ve (7.18)’deki koşullu yüzdeler hesaplanır \([f_2 (x│v)\) ve \(g_1 (y│v)]\). Ağırlıklar, Grup2 için \(w_2=0\) alınırsa \(fs(x)\) değerleri Tablo 7.5’teki \(f(x)\) sütununa eşit olur. İşlemler Y formu üzerinde gerçekleştirilir.
![Tablo 7.7. Y formunun koşullu dağılımı [g_2(y|v)]](Sekil/Tablo10.PNG)
Tablo 7.7 Y formunun Grup2 için koşullu dağılımıdır. Eşitlik (7.13), Y formu ve Grup2 için yazılarak koşullu yüzdeler elde edilir.
\[g_2 (y│v)=\frac{g_2 (y,v)}{h_2 (v)}\]
Tablo 7.6’daki \(g_2(y,v)\) değerleri, ilgili sütunundaki \(h_2(v)\) değerlerine bölünür. Örneğin, Tablo 7.6’daki Y=1 ve v=0 için \(g_2(1,0)= 0,1\)’e eşittir. Bu değer \(v=0\) sütunundaki \(h_2\) değeri olan 0,13’e bölündüğünde Tablo 7.7’de \(g_2(1|0)\) için 0,154 elde edilir.
- Eşitlik (7.23)’te yer alan Y formunun Grup1’deki bileşik frekanslarını elde etmek için \(g_1(y,v)=g_2 (y|v) h_1 (v)\) değerleri hesaplanır.
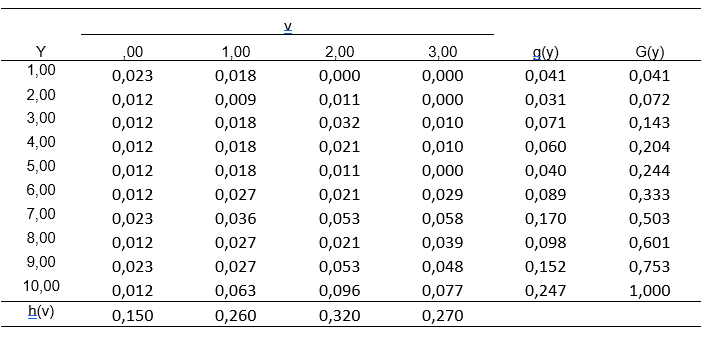
Tablo 7.8’deki \(g_2 (y│v)\) değerleri Tablo 7.5’deki \(h_1(v)\) değerleri ile çarpılır. Örneğin Tablo 7.7’daki \(g_2(1|0)\) değeri olan 0,154, Tablo 7.5’te \(v=0\) değerlerinin yüzdesinin toplamı olan 0,15 ile çarpılarak 0,023 elde edilmiştir. Bu şekilde elde edilen Tablo 7.8’in satır toplamlarındaki \(g(y)\) Y puanlarının yüzdesini, \(G(y)\) de toplamlı yüzdesini vermektedir.
- X ve Y formlarının yüzdelik sıraları bulunarak X formu puanları Y formu puanlarına eşitlenir.
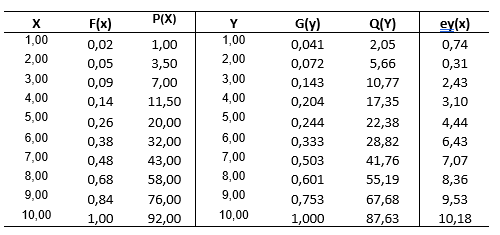
Tablo 7.9’da X ve Y Formlarının yüzdelik sıralarını gösteren \(P(x)\) ve \(Q(y)\) değerleri Eşitlik (7.4) ile elde edilmiştir.
Örneğin, x=2’nin yüzdelik sırası aşağıdaki formülle bulunur.
\(P(x)=100x{F(x^*-1)+[x-(x^*-0,5)]x[F(x^*)-F(x^*-1)]}\)
\(x^*=2\), \(F(x^*)=0,05\) ve \(F(x^*-1)=0,02\) olduğundan,
\(P(2)=100x{(0,02)+[2-(2-0,5)]x(0,05-0,02)}\)
\(P(2)=100x{(0,02)+(0,5x0,03)}\)
\(P(2)=3,50\) bulunur.
Puanların yüzdelik sıralarının bulunmasından sonra Eşitlik (7.9)’dan yararlanarak X formu puanları Y formuna eşitlenir.
\[e_{Ys} (x)=Q_s^-1 [P_s (x)]\]
\[e_{ys}(x)=\frac{P^*/100-G(y_U^*-1)}{G(y_U^*)-G(y_U^*-1)}+(y_U^*-0,5)\]
\(P^*/100=\frac{3,50}{100} = 0,035\)
\(y^*_u=2\)
\(y^*_u-1=1\)
\(G(y^*_u)=0,072\)
\(G(y^*_u-1)=0,041\)
\(e_y(2)=\frac{0,035-0,041}{0,072-0,041}+(2-0,5)\)
\(e_y(2)=0,31\)
Bu şekilde, X formundaki tüm puanlar Y formuna eşitlenir. Eşitlenmiş puanların 0,74 ile 10,18 arasında değişmekte olduğu ve ham puan ranjının dışına taştığı görülmektedir.
Zincirleme Eşit Yüzdelikli Eşitleme
Angoff (1971) tarafından doğrudan eşit yüzdelikli eşitleme olarak adlandırılan zincirleme eşit yüzdelikli eşitlemede X ve Y formları tek grup tasarımı kullanılarak ortak maddeler aracılığıyla birbirlerine eşitlenir. Bu yöntemde, Grup1’in X formu puanları, ortak maddelerdeki puanlara dönüştürülür. Daha sonra ortak maddelere dönüştürülmüş X formu puanları, Grup2’nin Y formu puanlarına dönüştürülür. Bu iki dönüşüm birbirine zincirlenerek X formu puanlarından Y formu puanlarına bir dönüşüm elde edilir.
Zincirleme eşit yüzdelikli eşitleme, tek grup deseni kullanılarak iki adımda gerçekleştirilir.
Birinci adım: Grup1’in X Formu puanlarını ortak maddelerdeki puanlarına dönüştürmek için tek grup deseni için tanımlanan Eşitlik (7.7) uygulanır. Fonksiyon, \(e_V1(x)\) olarak adlandırılır.
İkinci adım: Ortak madde puanlarına dönüştürülen X formunun puanları Y formunun puanlarına dönüştürülür. Bu dönüşüm için de tek grup deseni için tanımlanan Eşitlik (7.7) uygulanır ve fonksiyon \(e_Y2(v)\) olarak adlandırılır. Zincirleme eşit yüzdelikli eşitleme ilişkisi Eşitlik (7.28) ile gösterilebilir (Kolen & Brennan, 2014).
\[ e_y (chain)=e_{Y2}[e_{V1}(x)] \quad (7.28) \]
Zincirleme eşit yüzdelikli eşitleme, frekans tahmini yönteminden çok daha az hesaplama yoğunluğuna sahip olmasına rağmen toplam test puanları ve ortak madde puanları arasındaki ilişkiyi dikkate almadığı için teorik eksikliklere sahiptir (Kolen & Brennan, 2014). Birincisi, bu yöntem uzun bir test (toplam test) kısa bir teste (ortak maddeler) eşitlemeyi içermektedir. Uzun ve kısa testlerdeki puanlar, birbirinin yerine kullanılabilecek şekilde eşitlenemez. Yöntemin ikinci eksikliği, sentetik evren ile çalışmamasıdır. Bu nedenle ilişkinin hangi evren için geçerli olduğu belirsizdir.