BÖLÜM2 Örtük Sınıf Analizi
Örtük sınıf analizi bireyler içerisindeki örtük sınıfların kategorik gözlenen değişkenler üzerinden keşfedildiği örtük değişken modelidir. Örneğin bir şeyin varlığı veya yokluğu üzerinden yapılan ikili (dichotomous) değerlendirmeler, çoktan seçmeli yanıtlanan ve ikili puanlanan maddeler veya kategorik yanıtların alındığı ölçme araçlarındaki (örn: anket) maddeler kullanılarak bu tür bir model oluşturulabilir. Bu modellerde gözlenen değişkenler toplam puanlar değil ayrı ayrı madde puanlarıdır ve bu maddelerin birlikte bir boyut oluşturması ya da toplanabilirlik özelliği göstermesi şart değildir.
Gözlenen değişkenlerin kategorik olduğu ve modelin tek düzeyli (single-level) olduğu örtük sınıf modelleri oluşturmak için R’daki “poLCA” paketi kullanışlıdır.
Bir örnek olarak “poLCA” paketinin example dataları arasında yer alan ve ABD Ulusal Seçim Araştırmasından (2000 yılı) elde edilen anket verileri bu tür bir modelleme ile analiz edilebilir. Bunun için öncelikle “poLCA” paketini yükleyelim ve kütüphaneden çağıralım.
## Loading required package: scatterplot3d## Loading required package: MASSKod Bloğu 1. poLCA’nın kurulması ve çağırılması
Daha sonra ABD ulusal seçim araştırması datasını (election) analiz datası olarak çağıralım ve ardından ilk on satırını inceleyelim.
## MORALG CARESG KNOWG LEADG
## 1 3 Not too well 1 Extremely well 2 Quite well 2 Quite well
## 2 4 Not well at all 3 Not too well 4 Not well at all 3 Not too well
## 3 1 Extremely well 2 Quite well 2 Quite well 1 Extremely well
## 4 2 Quite well 2 Quite well 2 Quite well 2 Quite well
## 5 2 Quite well 4 Not well at all 2 Quite well 3 Not too well
## 6 2 Quite well 3 Not too well 3 Not too well 2 Quite well
## DISHONG INTELG MORALB CARESB KNOWB
## 1 3 Not too well 2 Quite well 1 Extremely well 1 Extremely well 2 Quite well
## 2 2 Quite well 2 Quite well <NA> <NA> 2 Quite well
## 3 3 Not too well 2 Quite well 2 Quite well 2 Quite well 2 Quite well
## 4 2 Quite well 2 Quite well 2 Quite well 3 Not too well 2 Quite well
## 5 2 Quite well 2 Quite well 1 Extremely well 1 Extremely well 2 Quite well
## 6 2 Quite well 2 Quite well 2 Quite well <NA> 3 Not too well
## LEADB DISHONB INTELB VOTE3 AGE EDUC GENDER PARTY
## 1 2 Quite well 4 Not well at all 2 Quite well 2 49 5 1 5
## 2 3 Not too well <NA> 1 Extremely well NA 35 4 2 3
## 3 3 Not too well 3 Not too well 2 Quite well 1 57 3 2 1
## 4 2 Quite well 3 Not too well 1 Extremely well 1 63 4 1 3
## 5 2 Quite well 3 Not too well 2 Quite well 2 40 5 2 7
## 6 2 Quite well 2 Quite well 2 Quite well 1 77 2 1 1Kod Bloğu 2. Veri setinin incelenmesi
Anket maddelerini yanıtlayan katılımcılar adayların (Al Gore ve George W. Bush) özellikleri ile ilgili düşüncelerini (ahlaklı, şefkatli, bilgili, iyi, sahtekar, akıllı) dört seçenekten birini işaretleyerek belirtmişlerdir. Seçenekler özelliğin adaydaki varlığının gücünü kategorilendirmektedir. Veri setinde ayrıca katılımcıların oy potansiyeli (VOTE3), yaşı (AGE), eğitim düzeyi (EDUC), cinsiyeti (GENDER), ve parti eğilimi (PARTY) değişkenlerinin de olduğunu görüyoruz.
Şimdi örtük sınıf modellerimizde kullanacağımız regresyon denklemimizi (formula) oluşturalım:
Kod Bloğu 3. Analiz denkleminin oluşturulması
Burada formülümüzü (f) oluştururken “cbind” fonksiyonu ile bağımsız değişkenlerimizi yani katılımcıların hem Gore hem de Bush için verdikleri yanıtları (gözlenen değişkenler) belirttik ve ~1 ile denklemimize bir sabit terim (intercept) ekledik. Bu aşamadan sonra modellerimizi kurup test etmeye hazırız. Bu aşamada bir sınıflı modelden sekiz sınıflı modele kadar (sekize kadar gitmek şart değil) oluşturacağız ve hangi modelin veriye daha uygun olduğunu belirlemeye çalışacağız.
lca1 <- poLCA(f,election,nclass=1, maxiter=10000)
lca2 <- poLCA(f,election,nclass=2, maxiter=10000)
lca3 <- poLCA(f,election,nclass=3, maxiter=10000)
lca4 <- poLCA(f,election,nclass=4, maxiter=10000)
lca5 <- poLCA(f,election,nclass=5, maxiter=10000)
lca6 <- poLCA(f,election,nclass=6,maxiter=10000)
lca7 <- poLCA(f,election,nclass=7,maxiter=10000)
lca8 <- poLCA(f,election,nclass=8,maxiter=10000)
Çıktıları görebilmek adına buradan örneğin üç örtük sınıflı modelin sonuçlarını alalım.
## Conditional item response (column) probabilities,
## by outcome variable, for each class (row)
##
## $MORALG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1013 0.5990 0.2552 0.0446
## class 2: 0.5224 0.4109 0.0390 0.0277
## class 3: 0.1851 0.3668 0.2350 0.2131
##
## $CARESG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0227 0.5090 0.3819 0.0864
## class 2: 0.3970 0.4605 0.0895 0.0529
## class 3: 0.0879 0.2546 0.3524 0.3051
##
## $KNOWG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0429 0.8058 0.1408 0.0105
## class 2: 0.5878 0.3543 0.0266 0.0312
## class 3: 0.2542 0.4253 0.2382 0.0822
##
## $LEADG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0207 0.4886 0.4268 0.0639
## class 2: 0.3747 0.4772 0.1085 0.0396
## class 3: 0.0747 0.2582 0.3856 0.2816
##
## $DISHONG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0519 0.2182 0.4998 0.2301
## class 2: 0.0426 0.0487 0.3371 0.5717
## class 3: 0.2007 0.3060 0.2774 0.2158
##
## $INTELG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0600 0.7953 0.1317 0.0130
## class 2: 0.5763 0.3698 0.0197 0.0341
## class 3: 0.2936 0.4407 0.1852 0.0805
##
## $MORALB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0642 0.7137 0.2164 0.0057
## class 2: 0.0966 0.3795 0.3638 0.1601
## class 3: 0.5797 0.3787 0.0248 0.0168
##
## $CARESB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0093 0.4847 0.4380 0.0679
## class 2: 0.0162 0.1125 0.4045 0.4668
## class 3: 0.3483 0.5362 0.0836 0.0319
##
## $KNOWB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0191 0.7583 0.2182 0.0045
## class 2: 0.0682 0.3115 0.3828 0.2374
## class 3: 0.4970 0.4899 0.0132 0.0000
##
## $LEADB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0537 0.7119 0.2217 0.0127
## class 2: 0.0236 0.2735 0.4524 0.2505
## class 3: 0.5106 0.4648 0.0187 0.0058
##
## $DISHONB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0134 0.1471 0.5683 0.2711
## class 2: 0.0862 0.3096 0.4111 0.1931
## class 3: 0.0365 0.0740 0.1993 0.6902
##
## $INTELB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0435 0.7741 0.1796 0.0028
## class 2: 0.1179 0.3391 0.3440 0.1990
## class 3: 0.5284 0.4656 0.0060 0.0000
##
## Estimated class population shares
## 0.4194 0.3198 0.2608
##
## Predicted class memberships (by modal posterior prob.)
## 0.4256 0.3166 0.2578
##
## =========================================================
## Fit for 3 latent classes:
## =========================================================
## number of observations: 1311
## number of estimated parameters: 110
## residual degrees of freedom: 1201
## maximum log-likelihood: -16714.66
##
## AIC(3): 33649.32
## BIC(3): 34218.96
## G^2(3): 15016.7 (Likelihood ratio/deviance statistic)
## X^2(3): 16748685096 (Chi-square goodness of fit)
## Kod Bloğu 4. Örnek model çıktısı
2.1 Uygun Modelin Belirlenmesi
Model çıktılarında AIC ve BIC değerlerinin yer aldığını görüyoruz. Bu değerleri veriye en uygun modelin belirlenmesinde kullanabiliriz. Bir örtük sınıflı modelden başlayarak son test ettiğimiz modele kadar yamaç birikinti grafiği oluşturalım (Şekil 3).
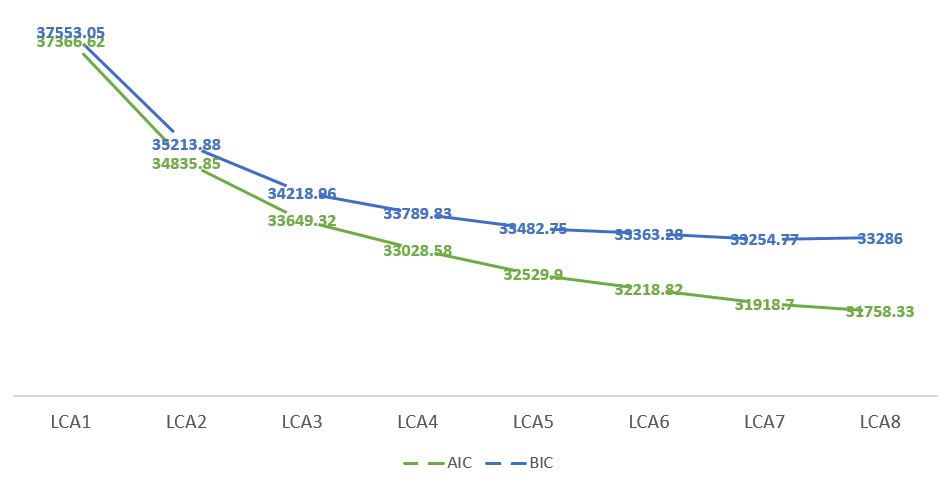
Grafiğin büküm noktası (inflection point) modellerden alınan değerler arasındaki farkın artık azalmaya başlayacağı noktayı ifade ettiği için veriye uygun modelin belirlenmesi konusunda fikir verebilir. Grafik incelendiğinde büküm noktasının lca4 yani dört örtük sınıflı modele denk geldiği söylenebilir. Bu durumda kararsız kalındığında ardışık iki modelin istatistiksel olarak karşılaştırılabilmesi için Lo-Mendell-Rubin (LMR) likelihood ratio testi kullanılabilir. Bu test daha fazla parametre içeren modeldeki (daha karmaşık model) yeni parametrelerin veri setini daha iyi açıklayıp açıklamadığını belirler. Normalde “poLCA” kütüphanesinde kolayca LMR testi çıktısı alabileceğimiz bir fonksiyon bulunmuyor. Fakat burada oluşturduğumuz modellerin çıktılarıyla “tidyLPA” kütüphanesindeki “calc_lrt” fonksiyonunu kullanarak LMR test sonuçlarına ulaşmamız mümkün. Burada örneğin grafiğin büküm noktası olarak düşündüğümüz lca4 modeli ile ardından gelen lca5 modelini veriye uygunluk bakımından karşılaştıralım [null modelimiz lca4 (mod_null) alternatif modelimiz lca5 (mod_alt) olsun]:
## You can use the function citation('tidyLPA') to create a citation for the use of {tidyLPA}.
## Mplus is not installed. Use only package = 'mclust' when calling estimate_profiles().mod_null <- lca4
n <- mod_null$Nobs
null_ll <- mod_null$llik
null_param <- mod_null$npar
null_classes <- length(mod_null$P)
mod_alt <- lca5
alt_ll <- mod_alt$llik
alt_param <- mod_alt$npar
alt_classes <- length(mod_alt$P)
calc_lrt(n, null_ll, null_param, null_classes, alt_ll, alt_param, alt_classes)## Lo-Mendell-Rubin ad-hoc adjusted likelihood ratio rest:
##
## LR = 638.924, LMR LR (df = 37) = 610.572, p < 0.001Kod Bloğu 5. LMR testi ile iki farklı modelin uygunluğunu karşılaştırma
Kod Bloğu 5’te LMR testi çıktıları incelendiğinde beşinci örtük sınıfın modele dahil edilmesiyle eklenen yeni parametrelerin veriyi daha iyi açıkladığı (p < 0.001) anlaşılmaktadır. Ancak yine de hatırlatmak gerekir ki her şey istatistik değildir. Örtük sınıf analizi incelenen topluluklar arasındaki gizil grupları (kendi içlerinde birbirine benzeyen ve bazı özellikler bakımından diğer gruplardan ayrışan topluluklar) ortaya çıkarmaya yönelik keşfedici bir analiz yöntemidir. İstatistikler kâşife yol gösterir fakat kâşifin örtük sınıfları tanımlayacak ve anlamlandıracak bilgi birikiminin olması önemlidir. Örtük sınıflardaki toplulukların birbirlerinden dikkate değer derecede farklılaşıp farklılaşmadıkları araştırmanın amacına ve gözlenen değişkenlerdeki özelliklerin hangilerinin araştırmacı tarafından incelemeye değer bulunup bulunmadığına da bağlıdır. Diğer taraftan bu örtük sınıfların büyüklüğü de önemlidir. Bu konuda genel bir kural olmamakla birlikte örneğin toplam popülasyonun %1 gibi küçük bir yüzdesine karşılık gelen bir gizil sınıfı araştırmacı incelemeye değer bulabilir veya bulmayabilir. Bu küçük sınıfın ayrıştırılması veriye daha uygun olsa da bu ayrışma araştırma amacına gerekli katkıyı sağlamıyorsa göz ardı edilebilir ve incelemeler daha az karmaşık olan model üzerinden sürdürülebilir. Biz bu örnekte daha yorumlanabilir olduğu gerekçesiyle lca4 modeli üzerinden devam ediyoruz.
2.2 Örtük Sınıfların Tanımlanması ve Adlandırılması
Bu aşamanın örtük değişken modellerinde en zor ve en fazla uzmanlık gerektiren aşama olduğu söylenebilir. Farklı örtük sınıflarda yer alan toplulukların özelliklerini inceleyerek ortak temsiliyetlerini bir anlamda kimliklerini ortaya çıkaracağız ve bunu yaparken gözlenen değişkenlerdeki düzeylerine (koşullu olasılıklar üzerinden) bakacağız. Sözü edileni somutlaştırmak bakımından Kod Bloğu 6’dan lca4 modelimizin çıktılarını tekrar inceleyelim.
## Conditional item response (column) probabilities,
## by outcome variable, for each class (row)
##
## $MORALG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.2459 0.4245 0.1876 0.1420
## class 2: 0.0157 0.3072 0.4552 0.2218
## class 3: 0.5980 0.3367 0.0359 0.0295
## class 4: 0.1748 0.7191 0.1061 0.0000
##
## $CARESG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1169 0.3232 0.3157 0.2442
## class 2: 0.0115 0.1129 0.5784 0.2973
## class 3: 0.4733 0.3993 0.0770 0.0503
## class 4: 0.0526 0.7061 0.2174 0.0239
##
## $KNOWG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.3433 0.4406 0.1491 0.0670
## class 2: 0.0179 0.5513 0.3604 0.0704
## class 3: 0.6852 0.2621 0.0222 0.0306
## class 4: 0.0980 0.8531 0.0489 0.0000
##
## $LEADG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1026 0.3349 0.3361 0.2264
## class 2: 0.0104 0.0749 0.6496 0.2651
## class 3: 0.4555 0.4121 0.0978 0.0347
## class 4: 0.0408 0.7078 0.2437 0.0078
##
## $DISHONG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1661 0.2404 0.3404 0.2531
## class 2: 0.1867 0.4129 0.2700 0.1305
## class 3: 0.0535 0.0465 0.3008 0.5991
## class 4: 0.0048 0.1133 0.5578 0.3241
##
## $INTELG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.3878 0.4358 0.1186 0.0579
## class 2: 0.0438 0.5816 0.2955 0.0790
## class 3: 0.6947 0.2552 0.0139 0.0363
## class 4: 0.0896 0.8549 0.0555 0.0000
##
## $MORALB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.6637 0.2974 0.0273 0.0115
## class 2: 0.1775 0.6444 0.1535 0.0246
## class 3: 0.1071 0.3477 0.3612 0.1840
## class 4: 0.0444 0.6889 0.2515 0.0152
##
## $CARESB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.4265 0.4521 0.0969 0.0246
## class 2: 0.0487 0.6476 0.2573 0.0465
## class 3: 0.0181 0.0938 0.3883 0.4997
## class 4: 0.0062 0.3713 0.4808 0.1417
##
## $KNOWB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.6427 0.3573 0.0000 0.0000
## class 2: 0.0447 0.7903 0.1518 0.0132
## class 3: 0.0733 0.3089 0.3455 0.2723
## class 4: 0.0204 0.6656 0.2905 0.0236
##
## $LEADB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.6200 0.3600 0.0152 0.0047
## class 2: 0.1089 0.7578 0.1240 0.0092
## class 3: 0.0177 0.2537 0.4301 0.2985
## class 4: 0.0433 0.6129 0.3124 0.0313
##
## $DISHONB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0355 0.0690 0.1945 0.7011
## class 2: 0.0339 0.1221 0.3938 0.4502
## class 3: 0.1048 0.3418 0.3576 0.1957
## class 4: 0.0079 0.1638 0.6145 0.2138
##
## $INTELB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.6754 0.3246 0.0000 0.0000
## class 2: 0.0748 0.8112 0.1140 0.0000
## class 3: 0.1293 0.3233 0.3261 0.2214
## class 4: 0.0427 0.6872 0.2394 0.0306
##
## Estimated class population shares
## 0.194 0.218 0.2455 0.3424
##
## Predicted class memberships (by modal posterior prob.)
## 0.1899 0.2212 0.241 0.3478
##
## =========================================================
## Fit for 4 latent classes:
## =========================================================
## number of observations: 1311
## number of estimated parameters: 147
## residual degrees of freedom: 1164
## maximum log-likelihood: -16367.29
##
## AIC(4): 33028.58
## BIC(4): 33789.83
## G^2(4): 14321.96 (Likelihood ratio/deviance statistic)
## X^2(4): 6643424841 (Chi-square goodness of fit)
## Kod Bloğu 6. Uygun modelin incelenmesi
Model çıktıları incelendiğinde, keşfedilen örtük sınıfların büyüklükleri predicted class memberships başlığı altında görülebilir. Burada analizin her tekrarlanışında sınıfların yerlerinin random şekilde değiştiğini söylemekte fayda görüyoruz çünkü kitapta kod blokları kullandığımız için sayfanın her açılışında analiz yenilenmekte ve sınıfların yerleri değişmektedir. Bu durum sonucu etkilemese de çıktıda yer alan olasılıkları metin içerisinde yorumlamamızı olanaksız kılmaktadır. Genel bir yorum olarak sınıfları tanımlamaya çalışırken bakılması gereken yer her bir sınıftaki topluluğun gözlenen değişkenin hangi düzeyine ne olasılıkla tepki verecek (kestirilmiş) olduğunun incelenmesidir. Örneğin Class 1’deki bireylerin Al Gore’un ne kadar ahlaklı bir lider olduğu ile ilgili tepkileri (MORALG) incelendiğinde yüzde kaç olasılıkla “Extremely well” seçeneğine tepki verecekleri (yönelecekleri) veya yüzde kaç olasılıkla “Not well at all” seçeneğine yönelecekleri görülebilmektedir. Class 1’deki bireylerin Al Gore ile ilgili ve George W. Bush ile ilgili diğer maddelere verecekleri tepkiler de incelendiğinde bu grubun politik kimliği veya oy verme eğilimleri ile ilgili bir tanımlamaya gidilebilir. Yine vurgulamak gerekir ki örneğin bu araştırmada bunu yapabilmek için sadece istatistik bilmek yeterli olmamakta Amerikan siyaseti ve sosyolojisi ile ilgili de bilgi sahibi olmak gerekmektedir. Kod Bloğu 6’da yer alan olasılık tablosunu daha kolay yorumlayabilmek için grafik çizdirmek faydalı olabilir. Bunun için plot fonksiyonu oldukça kullanışlıdır (Şekil 4).

Şekil 4.Örtük sınıfların tepki olasılıkları grafiği
2.3 Birey Bazında Örtük Sınıf Üyeliklerinin Kestirilmesi
Örtük sınıf analizi ile örneğin bu seçim anketine katılan 1311 kişinin tek tek hangi örtük sınıfa üye olabileceği de olasılıksal olarak kestirilebilmektedir. Bunun için posterior olasılıkları kestirdik ve round fonksiyonu ile virgülden sonra iki basamak olacak şekilde yuvarladık. Bu işlemi classmemberships olarak tanımlayalım (Kod Bloğu 7).
## [,1] [,2] [,3] [,4]
## [1,] 0.97 0.02 0.00 0.01
## [2,] 0.00 0.00 0.02 0.98
## [3,] 0.01 0.01 0.00 0.99
## [4,] 0.20 0.80 0.00 0.00
## [5,] 0.00 0.00 0.93 0.07
## [6,] 0.00 0.01 0.00 0.99Kod Bloğu 7. Örtük sınıf üyeliklerinin kestirilmesi
Kod bloğunda kalabalık oluşturmamak için classmemberships değişkeninin yalnızca ilk satırlarını görebilmek bakımından head fonksiyonu ile sınırlandırıldığını belirtelim. Görüldüğü üzere her bir bireyin farklı örtük sınıflarda yer alma olasılıkları (satırlar bireyleri, sütunlar örtük sınıfları ifade etmektedir) kestirilmiştir. Burada bireyler üye olma olasılığı en yüksek olan sınıfa atanmakta ve predicted class memberships değişkeni oluşturularak örtük sınıfların büyüklükleri (class sizes) belirlenmektedir. Ayrıca bireylerin örtük sınıf üyelikleri değişkeni ile sınıfların farklı değişkenler bakımından karşılaştırılmasını içeren ileri adım analizleri de gerçekleştirebilirsiniz.
2.4 Ortak (Covariate) Değişkenlerin Modele Eklenmesi
Aynı örnek üzerinden gidilecek olursa ABD vatandaşlarının Gore veya Bush’a oy verme eğilimlerini (veya onlara bakış açılarını) temsil eden sınıfların oluşmasında bireylerin parti aidiyetlerinin (demokrat veya cumhuriyetçi) bir ortak değişken olarak etkili olabileceği düşünülebilir. Bu durumda parti (PARTY) değişkenini denklemimize (f2) ortak değişken olarak ekleyerek örtük sınıfların oluşumuna bakabiliriz.
f2 <- cbind(MORALG,CARESG,KNOWG,LEADG,DISHONG,INTELG, MORALB,CARESB,KNOWB,LEADB,DISHONB,INTELB)~PARTY
lca42 <- poLCA(f2,election,nclass=4, maxiter=10000)## Conditional item response (column) probabilities,
## by outcome variable, for each class (row)
##
## $MORALG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.6096 0.3227 0.0363 0.0313
## class 2: 0.1044 0.3752 0.3056 0.2148
## class 3: 0.1428 0.6694 0.1790 0.0089
## class 4: 0.0433 0.8662 0.0905 0.0000
##
## $CARESG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.4627 0.4013 0.0783 0.0577
## class 2: 0.0357 0.2133 0.4536 0.2973
## class 3: 0.0375 0.6124 0.2985 0.0516
## class 4: 0.1410 0.8590 0.0000 0.0000
##
## $KNOWG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.6943 0.2295 0.0361 0.0401
## class 2: 0.1436 0.5211 0.2617 0.0735
## class 3: 0.0795 0.8328 0.0877 0.0000
## class 4: 0.0170 0.9830 0.0000 0.0000
##
## $LEADG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.4542 0.4122 0.0891 0.0445
## class 2: 0.0274 0.1822 0.5092 0.2812
## class 3: 0.0297 0.6219 0.3269 0.0215
## class 4: 0.0000 0.8801 0.1199 0.0000
##
## $DISHONG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0578 0.0624 0.2976 0.5821
## class 2: 0.1972 0.3492 0.2925 0.1611
## class 3: 0.0147 0.1452 0.5583 0.2818
## class 4: 0.0000 0.0576 0.2562 0.6862
##
## $INTELG
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.7178 0.2076 0.0298 0.0448
## class 2: 0.1691 0.5476 0.2067 0.0765
## class 3: 0.0776 0.8312 0.0912 0.0000
## class 4: 0.0000 1.0000 0.0000 0.0000
##
## $MORALB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1627 0.3668 0.3086 0.1619
## class 2: 0.4594 0.4962 0.0389 0.0055
## class 3: 0.0337 0.6859 0.2630 0.0174
## class 4: 0.0000 0.2120 0.6733 0.1146
##
## $CARESB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0470 0.1391 0.3867 0.4272
## class 2: 0.2601 0.6076 0.1130 0.0193
## class 3: 0.0048 0.3791 0.4936 0.1225
## class 4: 0.0000 0.0600 0.4115 0.5285
##
## $KNOWB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1319 0.3525 0.2904 0.2252
## class 2: 0.3504 0.5800 0.0696 0.0000
## class 3: 0.0140 0.6979 0.2647 0.0234
## class 4: 0.0000 0.1810 0.6073 0.2117
##
## $LEADB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.0776 0.2989 0.3949 0.2286
## class 2: 0.3932 0.5665 0.0359 0.0044
## class 3: 0.0347 0.6524 0.2831 0.0298
## class 4: 0.0000 0.0000 0.6401 0.3599
##
## $DISHONB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1010 0.3057 0.3578 0.2355
## class 2: 0.0165 0.0677 0.2841 0.6316
## class 3: 0.0185 0.1671 0.6072 0.2071
## class 4: 0.0000 0.4083 0.3538 0.2379
##
## $INTELB
## 1 Extremely well 2 Quite well 3 Not too well 4 Not well at all
## class 1: 0.1885 0.3671 0.2682 0.1761
## class 2: 0.3844 0.5740 0.0416 0.0000
## class 3: 0.0387 0.7109 0.2267 0.0238
## class 4: 0.0000 0.2104 0.5804 0.2092
##
## Estimated class population shares
## 0.2833 0.3266 0.3648 0.0253
##
## Predicted class memberships (by modal posterior prob.)
## 0.28 0.3262 0.3662 0.0277
##
## =========================================================
## Fit for 4 latent classes:
## =========================================================
## 2 / 1
## Coefficient Std. error t value Pr(>|t|)
## (Intercept) -5.05393 0.33722 -14.987 0
## PARTY 1.33800 0.08144 16.429 0
## =========================================================
## 3 / 1
## Coefficient Std. error t value Pr(>|t|)
## (Intercept) -1.37908 0.18986 -7.264 0
## PARTY 0.58881 0.06422 9.168 0
## =========================================================
## 4 / 1
## Coefficient Std. error t value Pr(>|t|)
## (Intercept) 15.19868 0.10322 147.249 0
## PARTY -16.72432 0.10322 -162.030 0
## =========================================================
## number of observations: 1300
## number of estimated parameters: 150
## residual degrees of freedom: 1150
## maximum log-likelihood: -16152.3
##
## AIC(4): 32604.59
## BIC(4): 33380.11
## X^2(4): 8331461201 (Chi-square goodness of fit)
##
## ALERT: estimation algorithm automatically restarted with new initial values
## Kod Bloğu 8. Ortak değişken ile dört sınıflı modelin oluşturulması
Kod Bloğu 8’de doğrudan ortak değişken eklenmiş dört sınıflı modeli oluşturduk fakat normalde uygun modelin belirlenebilmesi için daha önceki aşamaların tümünden tekrar geçmek gerekiyor. Buradaki amacımız ortak değişken eklenmiş ve eklenmemiş dört sınıflı modellerin siz okuyucular tarafından karşılaştırılabilmesini sağlamaktır.