BÖLÜM1 Örtük Değişkenlerin Modellenmesi
Örtük değişken, doğrudan gözlemlenemeyen veya ölçülemeyen ancak gözlemlenebilir veya ölçülebilir verilere dayanarak ortaya konulmaya çalışılan değişkenlerdir. Örtük değişkenler, gözlemlenebilir değişkenler arasındaki ilişkilerin analiz edilmesi ile modellenmeye çalışılır. Tüm bilim alanlarında da olduğu gibi psikoloji ve eğitim bilimlerinde de kompleks durumlar teoriler ve modeller ile idealize edilmeye çalışılır. Örneğin Galileo, tavandan uzun zincirlerle sarkan lambaların sarkaçlar gibi salınım yaptığını gözlemlemiştir. Sarkacın her bir periyodu için zincir uzunluğu ve geçen süre arasında matematiksel bir formül geliştirmiştir. Geliştirdiği bu model rüzgar direnci, zincirin esnekliği gibi olası diğer faktörleri dikkate almadığından idealleştirilmiş bir modeldir (Asimov, 1972). Modeller açıklanmak istenen olgunun tüm detaylarını ortaya koymaya yetmese de operasyonel olarak kullanışlıdır (Demir, 2019). Örtük değişkenlerin varlığının ortaya konmasını, gözlenen değişkenler ve diğer örtük değişkenler ile ilişkilerini ortaya koyan modelleme yaklaşımı örtük değişken modelleme olarak adlandırılır.
Örtük değişken modelleme (latent variable modeling) bir veri setindeki gözlenen verilerden yararlanarak gözlenmeyen örtük grupları tanılamaya yarayan analitik bir analiz yöntemidir. Modellemenin temelleri ilk kez Lazarsfeld (1950) tarafından tanıtılmıştır ve Lazarsfeld bu tekniği örtük yapı analizi olarak tanımlamış ve iki kategorili değişkenlere dayalı tipolojiler oluşturmak için kullanmıştır. (Goodman, 1974a; 1974b), model parametrelerinin maksimum olabilirlik tahminlerini elde etmek için bir algoritma geliştirerek modeli pratikte uygulanabilir hale getirmiştir. Farklı kaynaklarda örtük değişken karma modelleme (latent variable mixture modeling), sonlu karma modelleme (infinite mixture modeling) olarak da karşılaşabileceğiniz bu model ailesi bu kitapta örtük değişken modelleme (ÖDM) olarak kullanılacaktır.
ÖDM, adından da anlaşıldığı gibi model temelli bir istatistiksel tekniktir. Kurulan tüm diğer modeller gibi örtük sınıf modellerinin de mutlak gerçeği yansıtmadığı ancak incelediğimiz değişkenlere bağlı olarak bilimsel dayanak sağlamada işlevsel olduğu unutulmamalıdır. Goodman (1979), ÖDM matematiksel gösterimini şöyle ifade etmiştir:
X örtük değişken, A,B ve C gözlenen değişkenler olmak üzere,
i=1, . . . , I ; j=1, . . . , J ; t=1, . . . , T ; k=1, . . . , K sınıfları için,
\[ \pi_{ijk}^{ABX} =\displaystyle\pi_k^X \pi_{ik}^{A/X} \pi_{jk}^{B/X} \]
\[ \begin{align*} \pi_{ijk}^{ABX} & = \text{Bir gözlemin, } A \text{'nın } i \text{, } B \text{'nin } j \text{, } X \text{'in } k \text{ sınıfında olma bileşik olasılığı} \\ \pi_k^X & = \text{Bir gözlemin } X \text{'in } t \text{ sınıfında olma olasılığı} \\ \pi_{ik}^{A/X} & = \text{A'nın } i \text{ kategorisinde yer alan bir gözlemin, } \\ & \quad X \text{'in } k \text{ sınıfında olma koşullu olasılığı} \\ \pi_{jk}^{B/X} & = \text{B'nin } j \text{ kategorisinde yer alan bir gözlemin,} \\ & \quad X \text{'in } k \text{ sınıfında olma koşullu olasılığı} \end{align*} \]
Goodman (1979) tüm parametrelerinin alabileceği değerleri maksimum olabilirlik tahmini adı altında açıklamıştır ve modeldeki sınıf olasılıkları ve koşullu olasılıkların alabileceği toplam değer 1’e eşittir.
\[ \sum_{k=1}^{K} \pi_k^X = 1 \]
Tüm örtük değişken modelleri sınıf içi ve sınıflar arası modelleri birleştirir (Sterba, 2013). Sınıf içi model, belirli bir k sınıfındaki, bu parametrelere göre nispeten homojen bir alt grup oluşturan kişiler için popülasyon parametrelerini tanımlar. Sınıflar arası model, her kişinin K sınıfının temelini oluşturan alt popülasyondan örneklenme olasılığını tanımlar. Böylece karma modeller, sınıf içi parametreler açısından benzer kişileri kümeler ve her sınıf için kişi başına bir sınıflandırma olasılığı sağlar. Daha sonra kişiler, en yüksek üyelik olasılıkla ait olabilecekleri örtük bir sınıfa atanabilirler. Dolayısıyla bir kişi %70 olasılıkla A sınıfına, %20 olasılıkla B sınıfına ve %10 olasılıkla C sınıfına ait olabilir. Bu olasılığa dayalı kümeleme, geleneksel kümeleme analizinde uygulanan deterministik atamaya göre ÖDM’nin önemli bir operasyonel farklılığıdır çünkü söz konusu sınıflandırma belirsizliğini olasılık temelli olarak hesaba katmaktadır (Bauer, 2007; Mair, 2018; Rost, 2003; Vermunt & Magidson, 2002). Bu fark aslında örtük değişken modellerinin geleneksel küme analizine göre en büyük avantajıdır çünkü sınıflandırma belirsizliği modelin bir parçası olarak kabul edilir. Ayrıca, Magidson ve Vermunt (2004), gerçek sınıf üyeliğinin bilindiği ve verinin kümeleme analizinin varsayımlarını karşılayacak şekilde üretildiği bir veri seti üzerinden örtük sınıf analizi (ÖSA) ve k-ortalama kümeleme analizinin sınıflama doğruluğunu inceledi. Çalışmada k-ortalama kümeleme analizi kullanıldığında yanlış sınıflandırma oranının ÖSA’ya göre yaklaşık dört kat daha yüksek olduğunu bulmuşlardır.
ÖDM, değişkenleri tanımlamak veya sınıflandırmak yerine, popülasyon içindeki heterojenliği bireylerin tepki yanıtları ile tanımlamak için bir çerçeve sağlar. Karma modeller arasında yer alan faktör analizi ile de bu yönüyle ayrılır. Faktör analizinde değişkenler gruplandırılırken ÖDM kişi merkezlidir. Kişi merkezli modeller bir popülasyonun benzer bireylerden oluşan alt gruplara göre ayrıştırılabilmesine odaklanır. Örtük değişken modeli ailesi altında yer alan analiz teknikleri Tablo 1’de özetlenmiştir.
Tablo 1. Örtük değişken modelleme türleri
| Analiz Tekniği | Değişken | Zaman |
|---|---|---|
| Örtük Sınıf Analizi (Latent Class Analysis) | Kategorik | Kesitsel |
| Örtük Profil Analizi (Latent Profile Analysis) | Sürekli | Kesitsel |
| Örtük Geçiş Analizi (Latent Trait Analysis) | Kategorik | Boylamsal |
| Karma Büyüme Modeli (Mixture Growth Modeling) | Sürekli | Boylamsal |
Tablo 1’de görüldüğü gibi teknikler gözlenen değişkenin ölçek düzeyine ve verinin kesitsel/boylamsal olma durumuna göre sınıflandırılmıştır. Aslında bu sınıflamanın modeller geliştikçe değiştiği ve yazılımların katkısıyla da sınırların gittikçe belirsizleştiğini söyleyebiliriz. Ancak kavramsal bir çerçeve çizebilmek ve kitaptaki akışı sağlayabilmek adına bir sınıflama yapmaya ihtiyaç vardır. Bu nedenle modelleri kesitsel ve boylamsal olmalarına göre sırayla tanıtacağız (R uygulamalarında sadece kesitsel tekniklere yer verilmiştir). Kesitsel veriler için eğer gözlenen değişken kategorikse Örtük Sınıf Analizi (ÖSA), sürekli ise Örtük Profil Analizi (ÖPA) olarak isimlendirilir. Benzer şekilde boylamsal veriler için eğer gözlenen değişken kategorikse Örtük Geçiş Analizi (ÖGA), sürekli ise Karma Büyüme Modeli olarak isimlendirilir.
1.1 Kesitsel Veriler için Örtük Değişken Modelleme
1.1.1 Örtük Sınıf Analizi
Örtük sınıf analizi (ÖSA) bir veri setindeki gözlenen kategorik verilerden yararlanarak gözlenmeyen örtük kategorik sınıfları tanılamaya yarayan istatistiksel bir analiz tekniğidir. Benzer özelliklere sahip bireylerin ait olabilecekleri grupları olasılıksal olarak tanımlamak için kullanılır. ÖSA, psikoloji ve eğitimde sıklıkla kullanılmasının yanı sıra tıp, hemşirelik gibi sağlık araştırmalarında ve pazar araştırmalarında da yaygın olarak kullanılır. ÖSA, bireyleri bir hastalığın belirtileri veya bir ürüne yönelik tutumlar gibi bir dizi gözlemlenebilir değişkene verdikleri yanıtlara göre gruplandırarak çalışır. Gruplar, ortak özellikleri paylaşan farklı birey sınıflarını temsil eder ve altta yatan örtük değişken sınıflarda yer alan bireylerin benzer özelliklerinden çıkarılır.
ÖDM başlığı altında verilen formülasyonu da inceleyerek, ÖSA’nın matematiksel modelini şu şekilde açıklayabiliriz: \(M\) gözlenen değişkeni temsil etsin (\(u_1, u_2, ..., u_M\)), \(n\) kişide gözlenmiş olsun. ÖSA modeli, \(M\) değişkenin tamamının, örtük sınıflara (\(K\)) sahip sırasız kategorik örtük sınıf değişkeninin (\(c\)) ölçümleri olduğunu varsayar. Her örtük sınıfın büyüklüğü \(P(c = k)\), \(\pi_k\) ile gösterilir.
Her bireyin \(K\) sınıflarından tam olarak birine üyeliği olduğunu ve \(\sum{\pi_k} = 1\) olduğunu varsayarız.
Koşullu bağımsızlık varsayımı altında ÖSA modeline ait dağılım şöyle ifade edilebilir:
\[ Pr(u_{1i}, u_{2i}, ..., u_{Mi}) = \sum_{k=1}^{K} \pi_{k} \left( \prod_{m=1}^{M} Pr(u_{mi} | c_{i} = k) \right) \]
Burada: \(Pr(u_{mi} | c_{i} = k)\), örtük sınıf \(k\) altında gözlenen değişken \(u_{mi}\)’nin olasılığını temsil eder.
Bu formül, ÖSA modelinin örtük sınıfların büyüklükleri ve her değişkenin bu sınıflara ait olma olasılıkları temelinde gözlenen değişkenlerin olasılıklarını hesapladığı bir modeli ifade eder.
ÖSA çoğunlukla iki kategorili değişkenler ile kullanılmaya başlandıysa da teorik olarak değişkenin kategori sayısı farklı da olabilir. Modelde gözlenen değişkenler toplanarak sürekli bir değişken elde edilmesi yerine değişkenler sınıflama ölçeği düzeyinde ele alınır. İkili puanlanan (1-0) maddeler, çoklu kategorik puanlanan maddeler, anket maddelerinden elde edilen veriler gibi farklı kategorik değişkenler kullanılarak modelleme yapılır. ÖSA’da gözlenen değişkenler arasında yerel bağımsızlık olarak aşina olduğumuz koşullu bağımsızlık varsayımı bulunur. Gözlenen değişkenler arasındaki ilişkinin tamamen örtük sınıf değişkeni ile açıklandığı varsayılır yani koşullu bağımsızlık varsayımı örtük sınıf üyeliğinin gözlemlenen değişkenler arasındaki paylaşılan varyansın tamamını açıkladığını, gözlenen değişkenlerin hataları arasında herhangi bir ilişkinin olmadığı anlamına gelir. Dolayısıyla değişkenlerin ikili hata varyansları arasındaki ilişki incelediğinde değerlerin düşük olması beklenir.
1.1.2 Örtük Profil Analizi
Örtük Profil Analizi (ÖPA), kesitsel verileri kullanması açısından ÖSA’ya benzer, ancak ÖPA, kategorik gözlenen değişkenleri kullanmak yerine sürekli yapıdaki gözlenen değişkenler kullanarak örtük grupları tahmin etmeye çalışır (Muthén ve Muthén, 2000). Dolayısıyla bu iki analiz aslında birbiri ile çok benzerdir ve sıklıkla aynı çatı altında değerlendirilir. ÖPA ile belirlenen gruplara profil adı verildiği gibi sınıf adı da verilmektedir. Bunun nedeni özellikle burada olduğu gibi modellerin teorik temellerini açıklarken iki modelin birbirine benzer olmasından dolayı her başlık altında profil/sınıf olarak ifade etmenin gereksiz olmasıdır. Bu nedenle kesitsel modellerle ilgili teorik bilginin verildiği sonraki başlıklarda sınıf olarak kullanmaya devam edeceğiz.
ÖPA’da M gözlenen sürekli değişkeninde i kişisine ait
\(X_i\) gözlenen değeri için, k sınıfındaki \(\mu_k\) ortalama ve \(\sigma_k^2\) varyansı için modelin matematiksel gösterimi şöyledir:
\[ f(x_i) = \sum_{k=1}^{K} \pi_k f_k(x_i | \mu_k, \sigma_k^2) \]
ÖSA’dan farklı olarak ÖPA’daki örtük sınıflar yerel bağımsızlık varsayımıyla belirlenmez ve ortaya çıkan en uygun modelleme sınıf üyeliğine bağlı olarak her gözlenen değişkenindeki farklı ortalama puanlarla tanımlanır (Williams ve Kibowski, 2016). Bauer (2007), ÖPA’da, sürekli değişkenler için Poisson gibi başka dağılımlar mümkün olsa da, genellikle her bir örtük sınıf içinde normal bir dağılım varsayıldığını ancak normallik varsayımının yalnızca bu alt popülasyon dağılımları için geçerli olduğunu, bunların ortak dağılımları için geçerli olmadığını ve test edilemez olduğunu ifade etmiştir. ÖPA’da ÖSA’dan farklı olarak dikkat edilecek bir diğer husus gözlenen değişkenlerin yalın halleriyle mi yoksa birlikte mi modelleneceğine karar verilmesidir. Birlikte modelleme genellikle alt puanların bileşik ortalama, faktör puanları veya makul değerler (plausible values) olarak toplanması gibi düşünülebilir.
1.2 Veriye En Uygun Model Nasıl Belirlenir?
Bu başlığı, “Örtük Sınıf Sayısına Nasıl Karar Verilir?” Şeklinde değiştirseydik de yanlış olmazdı. Modelleme tek sınıflı model ile başlar yani tüm bireylerin tek bir örtük sınıfta olduğu varsayılır. Bunun nedeni bu modeli bir temel karşılaştırma modeli olarak kabul ederek sonraki model için karşılaştırma yapabilmektir. Daha sonraki modeller her bir modelleme girişimine örtük sınıf sayısı bir artırılarak devam eder. Dolayısıyla sırasıyla 1, 2, 3, 4, … örtük sınıfa sahip modeller denenerek hangi modelin daha iyi olduğuna karar verilir. Tam da bu noktada akla gelen sınıf sayısına nasıl karar vereceğim sorusuna verilebilecek en net cevap bizce şöyle:
Hiçbir zaman insanın kafasında böyle yekpare kristal top gibi parlayan tek bir sınıf sayısı olmuyor.
Örtük değişken modellerinde sınıf sayısına karar verme açımlayıcı faktör analizindeki faktör sayısına karar verme ve isimlendirmeyle benzerdir. Sınıf sayısını belirlerken elimizde üç temel dayanak vardır: model uyum istatistikleri, madde olasılık grafiği ve teorik kavramsal alt yapı. Model uyum istatistikleri ile ilgili detaylar bir sonraki başlık atında verilmiştir. Ancak burada da değinmek isteriz ki maalesef bu uyum istatistiklerinin hepsi her zaman aynı sınıf sayısını işaret etmiyor olabilir. Bu durumda teori kavramsallaştırma ön plana çıkmaktadır.
Uyum istatistiklerinin yanı sıra ortaya çıkan sınıflar arasındaki farklılığın anlamlı, açıklanabilir, yorumlanabilir ve faydalı olması araştırılmalıdır. Model uyumu ne olursa olsun yorumlanamayan açıklanamayan sınıflar çalışmaya katkı sunamaz. Burada şuna değinmek isteriz, sınıflarınız arasında açıklayamadığınız önemsiz görülen bir sınıf olabilir ve bu sınıf diğer sınıflarca açıklanamayan kişilerin bulunduğu sınıf olarak kabul edilebilir (Mair,2018). Elbette küçük örtük sınıflar (%5 ve altındaki) önemlidir, tıpkı azınlıkların toplumda temsil edilmesinin önemli olduğu gibi. Ancak açıklanamayan isimlendirilemeyen pek çok sınıf olması analizi anlamsızlaştırabilir ve bu durumda modelin irdelenmesi gerekir. Temelde sınıf içi varyansın küçük sınıflar arası varyansın büyük olması istenir ve bu durum bireylerin ölçülen özellikler bakımından homojen olarak aynı sınıf içinde gruplandığını ve oluşan sınıfların birbirinden farklı olduğunu yani popülasyonun heterojen sınıflardan oluştuğunu gösterir. Modelleri örtük sınıf sayısını artırarak denemenin bir diğer avantajı bir önceki modelde oluşan örtük sınıfların bir sonraki modelde nasıl ayrıştığını görmektir. Örneğin 3 sınıflı bir modelden sonra 4 sınıflı modeli denediğimizde ve 3. sınıfın ikiye ayrıldığını gözlemlediğimizde bu sınıfın belki de iki farklı örtük özellik taşıyan bireylerin bir araya gelmiş hali olabileceğini ve bu nedenle iki sınıfa ayrıldığını düşünerek detaylı inceleyebiliriz. Bu durum örtük özelliklerin açıklanmasında oldukça katkı sağlayıcı olabilir. Bir diğer yandan farklı sınıf sayısındaki modeller arasında sınıfların yapısının çok fazla değişiyor olması modelin uygun olmadığının bir göstergesi olabilir.
Farklı yazılımlar kullanarak analiz yapmak isterseniz sınıfların sıralamasının birbiri ile aynı olmadığını, bir yazılımda 1. sınıf olarak görülen sınıfın diğerinde 3. sınıf olabileceğini unutmayın. Bu durum bazı yazılımlarda analiz tekrarlandığında da olabilmektedir. Dolayısıyla sınıfları incelerken örtük özelliğin yapısı ve büyüklüklerini dikkate almak gerekir. Bazen analiz sırasında yazılımlardan aşırı parametre kullanımı, yetersiz tanılama uyarıları alabilirsiniz. Bu durum daha fazla sınıf oluşturmanın mümkün olmadığını göstermektedir dolayısıyla sınıf sayısını artırarak modelleme yapmayı bırakabiliriz.
Örtük sınıf sayısı belirlerken kullanılması gereken teorik alt yapı ve sınıfların yorumlanabilirliği, analizi yapan kişinin konu alanı ile ilgili uzmanlık düzeyine bağlıdır. Tıpkı ölçek geliştirme veya uyarlama sürecinde olduğu gibi kişi uzman olduğu ölçüde istatistiksel verileri değerlendirebilir hatta reddedebilir. Dolayısıyla bu konuda yapabileceğimiz en önemli uyarı yeterli teorik bilgiye sahip olmadığınız konularda örtük sınıf belirlemeye temkinli yaklaşmanızdır. Şimdi, istatistiksel sınıf sayısı belirleme tekniği olarak kullanabileceğiniz model uyum istatistikleri ve madde olasılık grafiğinden bahsedeceğiz.
1.3 Model Uyum İstatistikleri Nasıl Yorumlanır?
Modelleme, aslında gerçeğini bilmediğimiz durumlara mümkün olduğunca yaklaşma çabasıdır. Tüm ölçmelerde hatasız gerçek değeri bilemesek de mümkün olduğunca az hata ile gerçek değere yaklaşmaya çalışırız. Örtük değişken modellerinde de benzer şekilde gerçek örtük sayısını bilmiyoruz ancak mümkün olduğunca az hata ile belirlemek istiyoruz. Bu amaçla kullanılan model uyum istatistiklerini mümkün olduğunca sınıflayarak açıklayacağız. Bu bölümde ve modellerin uygulamalı gösteriminde uyum istatistiklerinin İngilizce kısaltmaları kullanılacaktır, toplu halde Tablo 2’de verilmiştir.
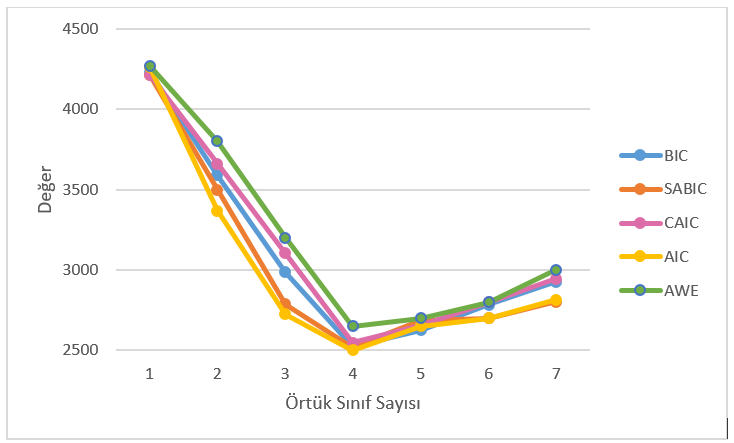
Model uyum istatistiği sınıflarından ilki bilgi kriterleri temelli sınıftır. Bunlardan en çok bilineni Shwarz (1978) tarafından geliştirilen Bayesian bilgi kriteridir (BIC, Bayesian information criterion).Diğerleri ise şöyle sıralanabilir: Akaike bilgi kriteri (AIC, Akaike information criterion), örneklem büyüklüğüne göre ayarlanmış Bayesian bilgi kriteri (SABIC, sample sizeadjusted Bayesian information criterion), tutarlı Akaike bilgi kriteri (CAIC, consistent Akaike information criterion), kanıt yaklaşık ağırlık kriteri (AWE, approximate weight of evidence criterion). Daha düşük bilgi kriteri değerleri daha iyi uyumu gösterir (Bozdogan, 1987; Banfield ve Raftery, 1993; Masyn, 2013; Morgan, 2015; Nylund, Asparouhov ve Muthén, 2007; Sclove, 1987; Weller vd., 2020). Modellemeye devam edildikçe BIC değeri düşmeye devam edebilir bu nedenle bilgi kriteri temelli indeksler için en iyi sınıflama sayısını belirlemek için açımlayıcı faktör analizindekine benzer yamaç-birikinti grafiği kullanılabilir. Bu grafikteki dirsek noktası belirlenerek model uyumundaki geri dönüşün veya iyileşmenin azaldığı noktanın belirlenerek sınıf sayısı için daha doğru tahminde bulunulabilir (Nylund-Gibson ve Choi, 2018; Petras ve Masyn, 2010). Şekil 1‘de örnek grafik verilmiştir. Bu grafik incelendiğinde dikey eksende verilen bilgi kriterlerine dayalı model uyum indeksleri değerlerinin yatay eksende verilen örtük sınıf sayısına göre değişimleri görülmektedir. Dirsek noktası (büküm noktası) 4 sınıflı modelde görülmüştür. Sınıf sayısı 4’e gelene kadar artıkça indeks değerleri düşmüş ancak bu sınıf sayısından sonra indekslerin değerleri artmaya başlamıştır. Dolayısıyla bu grafik göz önüne alındığında model uyum indekslerince önerilen örtük sınıf sayısının 4 olduğu ifade edilebilir.
Bayes temelli model uyum indeksleri sınıfında ise en yaygın kullanılan Bayes faktörü (BF, Bayes factor) ve doğru model olasılığı (cmP, correct model probability) indeksleridir. BF, iki ardışık sınıf modeli arasındaki model uyumunu karşılaştırır. Elde edilen BF değerine göre daha az sınıf sayısına sahip model için şöyle yorumlanır: 1 < BF < 3, zayıf model uyumu, 3 < BF < 10 orta model uyumu, BF > 10 ise güçlü model uyumu göstermektedir (Wagenmakers, 2007; Wasserman, 1997). Diğer model uyum indeksi cmP ise ismini doğru modelin modellerimizden biri olduğunu varsayarak hesaplama yapar ve en büyük cmP değeri en doğru model anlamına gelir.
Bir diğer sınıf olabilirliğe dayalı model uyum indeksleridir. Bu testler Vuong-Lo-Mendell-Rubin düzeltilmiş olabilirlik oranı testi (VLMR-LRT, Vuong-Lo-Mendell-Rubin likelihood ratio test), bootstrap olabilirilk oranı testi (BLRT, bootsrapped likelihood ratio test) olarak yaygın şekilde kullanılır (Lo vd., 2001; McLachlan ve Peel, 2000). VLMR-LRT ve BLRT örtük sınıf sayısını vermede çok fazla kullanılan güçlü istatistiksel tekniklerdir. Bu indeksler iki ardışık model arasındaki farkı inceler ve anlamlığa ilişkin bir p değeri üretir. Bu değerin anlamsız olduğu sınıf düzeyi görüldüğünde bir önceki sınıf düzeyi tercih edilir. Örneğin 1,2, ve 3 sınıflı modellerinizde VLMR-LRT ve BLRT p değerleri anlamlı ancak 4 sınıflı modelde anlamsız bir p değeri elde ettiyseniz bu durumda 4 sınıflı modele ihtiyacınız yoktur ve iyi uyum göstermiyordur. 3 sınıflı modelin en iyi model olması üzerine düşünebilirsiniz. Her ne kadar VLMR-LRT ve BLRT indekslerinin örtük sınıf belirlemede yeterli olduğunu belirten çalışmalar olsa da biz diğer model uyum istatistiklerini ve kavramsal yorumlanabilirliği dikkate alarak örtük sınıf sayısını belirlemenizi öneriyoruz.
Tablo 2. Model uyum indeksleri için 2N1K
| Ne? | Nasıl? | Kim? |
|---|---|---|
| Bilgi Kriterleri Temelli Model Uyum İndeksleri | ||
| BIC (Bayesian Information Criterion) | Shwarz (1978) | |
| AIC (Akaike Information Criterion | Akaike (1973) | |
| SABIC (Sample Size Adjusted Bayesian Information Criterion) | Bu gruptaki tüm indeksler için en düşük değere sahip model veya kendisinden sonra değerdeki düşüşün azaldığı model seçilir. | Sclove (1987) |
| CAIC (Consistent Akaike İnformation Criterion) | Bozdogan (1987) | |
| AWE (Approximate Weight of Evidence Criterion) | Banfield ve Raftery (1993) | |
| Bayes Temelli Model Uyum İndeksleri | ||
| BF (Bayes Factor) | İki ardışık sınıf sayılı modelde sınıf sayısı az model için model uyumu: 1 < BF < 3 ise zayıf, 3 < BF < 10 ise orta, BF > 10 ise güçlü | Wasserman (1997) |
| cmP (Correct Model Probability) | En yüksek cmP değeri en iyi modeli gösterir | Shwarz (1978) |
| Olasılık Temelli Model Uyum İndeksleri | ||
| VLMR-LRT (Vuong-Lo-Mendell-Rubin Likelihood Ratio Test) | Bu gruptaki testler için incelenen modelde p > .05 ise daha az karmaşık olan bir önceki modeli tavsiye eder. | Lo, Mendell ve Rubin (2001) |
| BLRT (Bootsrapped Likelihood Ratio Test) | McLachlan ve Peel (2000) |
1.4 Madde Tepki Olasılıkları Grafiği Nasıl Yorumlanır?
Önceki bölümde bahsedildiği gibi model uyum istatistikleri her zaman birbirleriyle tutarlı sonuçlar vermeyebilir. Bu noktada yardımınıza koşacak bir diğer veri kaynağı madde tepki olasılıkları grafiğini incelemektir. Örtük sınıf sayısı belirli bir model için madde tepki olasılık değerleri incelendiğinde aslında sınıfların birbirinden ne kadar iyi ayrıştığını da incelemiş oluruz. Şekil 2’de örnek bir koşullu madde tepki olasılıkları grafiği verilmiştir.
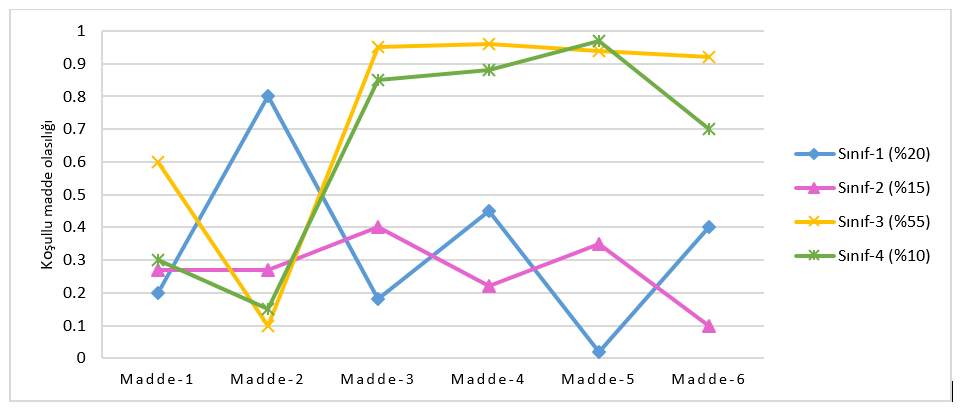
Şekil 2. incelendiğinde modelde gözlenen değişken olarak 6 madde bulunduğu ve 4 örtük sınıf oluşturulduğu görülmektedir. Elbette gerçek bir analiz durumunda bu sınıfların temsil ettikleri örtük özelliğe göre isimlendirilmesi beklenmektedir. Ancak burada analizin temel bilgilerini paylaştığımız için bir isimlendirme yapmayıp numaralandırılarak anlaşılmasını kolaylaştırmak istedik. Grafikte dikey eksende maddelerin koşullu olasılığı verilmiştir ve olasılık değerleri aralığında [0,1] değişmektedir. Yatay eksende ise analizde kullanılan 6 madde sıralanmıştır. Örtük sınıfların madde düzeyindeki koşullu olasılıkları renkli çizgilerle görülmektedir. Aynı zamanda her bir sınıfın göreceli büyüklüğü de isimlerinin yanlarında verilmiştir. Olası en büyük sınıfın (%55) Sınıf-3, en küçük sınıfın (%10) ise Sınıf-4 olduğu görülmektedir. Madde bazında sınıfların birbirinden ayrışmaları incelendiğinde örneğin Madde-1, Sınıf-3 hariç diğer sınıfları birbirinden ayırt edememiştir, Sınıf-1,2,4 neredeyse aynı değere sahiptir. Madde-2, Sınıf-1’i diğer sınıflardan ayırmada oldukça başarılıyken diğer üç sınıfı birbirinden ayırmamıştır. Sınıflara dikkat edecek olursak Sınıf-3 ve Sınıf-4 birbirine oldukça benzerdir ve sadece Madde-1 ile Madde-6’da birbirlerinden farklılaşmışlardır. Bu iki sınıf diğer maddelerde neredeyse birbiriyle aynı yapıyı temsil etmektedir, yani bu iki sınıfın bu maddelere verdikleri yanıt örüntüleri çok benzerdir diyebiliriz. Aynı zamanda Madde-6’ya dikkat edecek olursanız bu grafikte sınıfları birbirinden en iyi ayırt edebilen madde olduğu görülmektedir (Bu tür belirlemeler de yapıyı yorumlama noktasında işlevseldir). Sınıflar birbirinden ne kadar iyi ayırt edilebilirse model o kadar iyidir ve kavramsal olarak yorumlanabilmesi de o kadar kolaydır. Normalde yapacağınız modellemede kullanılan maddelerin içerikleri, ölçtükleri özellikler belli olduğundan maddelere verilen yanıt tepkilerine göre sınıfların özelliklerini, birbirlerinden ne kadar farklılaştıklarını belirlemek ve isimlendirmek için de bu koşullu olasılığı dayalı grafik oldukça faydalı olacaktır.
Örtük sınıfların birbirlerinden ne kadar iyi farklılaştırıldığını değerlendirmek için bir diğer verimiz ortalama sonsal olasılık (AvePP, average posterior probability) değerlerini incelemektir. Sınıflara ait AvePP değerinin ≥ .70 olması istenir, böylece sınıfların birbirlerinden iyi ayrıldıkları yorumunu yapabiliriz. (Nagin, 2005; Masyn, 2013). Bu değer belirlenen sınıfta yer alan bireylerin o sınıfa ait olma sonsal olasılıklarının ortalamasıdır. Bireyler ne kadar yüksek olasılıkla o sınıfa ait olurlarsa bu olasıklara ait ortalamaları da o kadar yüksek olacağından AvePP değeri yükselir. Tablo 3’te örnek bir sınıflama olasılığı tablosu verilmiştir.
Tablo 3. Sınıflama olasılıkları
| Sınıflar | Sınıf-1 | Sınıf-2 | Sınıf-3 | Sınıf-4 |
|---|---|---|---|---|
| Sınıf-1 | 0.905 | 0.076 | 0.009 | 0.010 |
| Sınıf-2 | 0.142 | 0.703 | 0.073 | 0.064 |
| Sınıf-3 | 0.003 | 0.000 | 0.951 | 0.046 |
| Sınıf-4 | 0.000 | 0.002 | 0.461 | 0.537 |
Sınıflama olasılıkları tablosunda köşegen değerleri AvePP değerlerini göstermektedir. Bu değerler Sınıf-1,2,3 için yüksekken Sınıf-4 için .537 değeri ile kabul edilebilir sınırın (.70) altındadır. Tabloda dikkat çeken bir başka durum Sınıf-4’e atanan bireylerin %46 olasılıkla Sınıf-3’te de yer alabileceğidir. Bu durumda Sınıf-4 ve Sınıf-3 arasındaki ayrımın farklılaşmadığı neredeyse yazı-tura atılmış gibi birbirlerinden ayrıldıkları söylenebilir.
Örtük sınıf sayısını belirlemekten ziyade örtük sınıf sayısı belirlendikten sonra doğruluğu ile ilgili destek verici kanıt olarak raporlanabilen bir başka indeks ise entropi değeridir. Bunun sebebi sınıf atamasındaki hata sınıf sayısının bir fonksiyonu olarak artabilir ve entropi değeri sınıf sayısının artmasına bağlı olarak değişebilir (Collins ve Lanza, 2010). Seçilen modelin entropi değerinin .80 değerinden büyük olması istenir ve .60’dan düşük değere sahip modeller kabul edilemez olarak yorumlanır.
1.5 Örneklem Büyüklüğü Ne Olmalıdır?
Öncelikle araştırmacılara örneklemin temsil yeteneğinin örneklem büyüklüğünden daha önemli olduğunu hatırlatmak istiyoruz. Teorik olarak örneklemin anlamı zaten popülasyonu temsil yeteneği olan popülasyon içindeki daha küçük bir grup olsa da pek çok araştırmacı çalışması için öncelikle kaç kişiden veri toplaması gerektiğini sorar. Oysa temsil yeteneği olmayan veya çok zayıf bir örnekleminiz varsa kaç kişiye ulaşırsanız ulaşın popülasyon adına çıkarımda bulunmanız hatalı olacaktır. Örneğin Türkiye’de kadınların kendilerini güvende hissetme düzeyi ilgili bir araştırma yapacağınızı düşünelim. Çalışmayı İzmir ili Karşıyaka ilçesinde yürütüyorsunuz ve burada veri topluyorsunuz. Bu ilçe sahil kenarında bulunuyor ve sahil boyunca yürüyüş ve bisiklet yolları, çeşitli spor ve oturma alanları vardır. Yaz ayları daha yoğunlukta olmak üzere bölgede yaşayan insanlar aile ve arkadaşlarıyla birlikte gece yarısından sonra dâhil olmak üzere bu alanlarda zaman geçirmektedir. Dolayısıyla burada yaşayan bir kadın gece 01.00’de rahatlıkla dışarı çıkıp yürüyüş yapıp evine geri dönebileceğini bilir ve kendini güvende hisseder. Tabi burada asıl problem örneklem ve istatistik değil ülkemizin her yerinde kadınların kendilerini yeterince güvende hissedememesidir. Örneğimize geri dönecek olursak çalışmanız için bu bölgeden 1000 kadın katılımcıya ulaşmış ve kendilerini güvende hissetme düzeyleri ile ilgili veri toplamış olsanız da bu veri elbette ve tekrardan maalesef Türkiye’ye genellenemeyecektir. Bunun yerine temsil yeteneği kuvvetli çok daha küçük bir örneklem daha etkili olacaktır. Kitabın yazarları İzmir’de yaşadığı için elbette okuyucu olarak İzmir övgüsünden kaçmanız mümkün olmadı bu nedenle okuyucular talep ettiği takdirde kitap yazarları İzmir’e yolu düşen her okuyucuya kahve ısmarlama sözü vermektedir.
Örneklem büyüklüğü ile ilgili olarak ÖDM literatüründe net bir büyüklük bulunmamaktadır. Ancak ÖSA için Finch ve Bronk (2011) minimum örneklem büyüklüğünün 500 olmasını önerirken bazı araştırmacılar ise minimum örneklem büyüklüğünün 300 ile 1000 arasında olmasını önermektedir (Morgan, 2015; Nylund-Gibson ve Choi, 2018). Net bir örneklem büyüklüğü belirlenememesinin sebebi kurulan modeldeki değişken sayısının ve sınıfların ne kadar iyi ayrışabildiğinin oldukça etkili olmasıdır. Sınıf sayısının en az olduğu örneğin 2 sınıf olduğu ve çok iyi ayrıştıkları bir durumda 100 kişiden az bir örneklem büyüklüğü bile kabul edilebilir. Ancak şunu da unutmamak gerekir ki daha önce bahsedilen azınlığı temsil eden sınıfların yani küçük hacimli sınıfların tespit edilebilmesi örneklemdeki kişi sayısı azaldıkça zorlaşacaktır. Masyn (2013) de düşük yaygınlıktaki sınıfların maskelenebileceğini belirtmiştir. Önceki paragrafta bahsettiğimiz durumla da bağlantı olarak aslında örneklemin temsilinde bir hata varsa bu daha da önemli hale gelecektir çünkü zaten popülasyonda büyüklüğü %1-5 olan küçük bir sınıfı belirleyememe olasılığınız artacaktır. Burada da araştırmacının alan bilgisinin ve literatür hakimiyetinin önemi ortaya çıkmaktadır çünkü sınıfları ne kadar iyi ayırabilen değişkenler, maddeler kullanılırsa o kadar iyi bir modellemeye daha az sayıda katılımcı ile ulaşılabilir.
1.6 Model Belirlendikten Sonra Ne Yapılır?
Veriye en uygun modeli belirledik, peki ya sonra? Bu aşamadan sonra artık elinizde incelediğiniz popülasyonun araştırma amacına uygun olarak bilimsel yöntemle keşfedilmiş ve iyi tanımlanmış alt tabakalarını, bu tabakaların büyüklüklerini ve bu tabakalara ait olan bireyleri kestirilmiş olasılıklar bağlamında görebiliyorsunuz demektir. Sürecin başında karanlık bir meydanda toplanmış bir grup kalabalık vardı ve şimdi tüm ışıklar yandı. Artık hangi grupların bir arada durduğunu ve hangi grupların birbirlerinden uzak durduğunu daha net görebiliyoruz. Bunun salt bir kümele işlemi olmadığını daha önce belirtmiştik. Çünkü elimizde bu grupların farklı durumlara nasıl tepki verebileceklerine ilişkin olasılıklar da var. Farklı gruplardaki bireyler bazı durumlara tepki olasılıkları bakımından benzeşiyor ve bazı spesifik durumlarda birbirlerinden ayrışıyor olabilirler. Elimizdeki gözlenen değişkenler ve bu örtük gruplar arasındaki ilişkilerin yorumlanması artık uygun modele karar verme amacını değil uygun modelin neleri açıkladığını okuyuculara aktarma amacını taşıyor. Bununla birlikte, farklı örtük gruplarda yer alan bireylerin araştırmayla ilgili olan diğer özelliklerini incelememiz de artık mümkündür. Örneğin sosyo-ekonomik düzeylerine göre birey dağılımları farklı örtük sınıflarda nasıl şekillenmiştir? Sorusuna kolayca yanıt verebiliriz. Öte yandan bu gruplardaki bireyleri bazı dışsal değişkenler bakımından birbirleri ile karşılaştırabiliriz. Bireylerin bu dışsal değişkene ilişkin düzeylerinin birbirlerinden anlamlı şekilde ayrışıp ayrışmadığını inceleyebiliriz. Bunun için bazı yaklaşım ve yöntemler bulunmaktadır. Fakat bu yaklaşım ve yöntemlere kitabın daha sonraki sürümlerinde yer verilmesi planlanmaktadır. Kitabın mevcut sürümünde kesitsel araştırmalara uygun örtük değişken modellerinin R uygulamalarına yer verilmiştir. Bu uygulamalarda veriye en uygun modelin belirlenmesine ve keşfedilen örtük sınıfların tanımlanmasına kadar olan süreçler ayrıntılarıyla ele alınmıştır.