Bölüm 3 Veri Düzenleme III
3.1 join()
join() fonksiyonları iki veri setini istenilen şekilde birleştirme amacıyla kullanılır. Örneğin elimizde A ve B olmak üzere iki farklı veri seti olsun. Her iki veri setini birleştirmek istediğimizde bu veri setlerinden hangi satır veya sütunları seçeceğimizi, satırların eşleşip eşleşmeyeceğini hangi değişkenlerle belirleneceğinin bilinmesi gerekmektedir. Bu nedenle de her bir amaca yönelik join fonksiyon türleri belirlenmiştir. Bunlar; left_join(), right_join(), full_join(), inner_join(), semi_join(), anti_join() fonksiyonlarıdır.
3.2 left_join()
A %>% left_join(B)ile A verisindeki tüm satırlar, mümkün olduğunda B verisi ile eşleştirilerek (olmadığında “NA” verir), hem A hem de B den gelen sütunlar alınır.

Şekil 1’de, left_join() fonksiyonu ile öncelikle X1 değişkenine ait tüm gözlemler alınmıştır. X2 değişkenine ait ID numarası “1” olan gözlem olmadığı için yeni veri setinde bu kısım kayıp veri (NA) olarak girilmiştir. Burada birleştirme yapılacak iki veri setine ait örnekteki gibi ortak bir değişkenin (“ID”) olması önemlidir.
Örnek bir veri seti üzerinden açıklayalım. midiPISA1, midiPISA verisinden OGRENCIID, CINSIYET ve ST097Q01TA, ST097Q02TA değişkenlerinin ve bu veri setinin ilk altı satırının seçilmesi ile oluşturulur.
midiPISA1 <- midiPISA %>% select(OGRENCIID,CINSIYET,ST097Q01TA,ST097Q02TA) #değişkenlerin seçimi
midiPISA1<-midiPISA1[1:6,] #veri setinin ilk 6 satırının seçilmesi
midiPISA1## # A tibble: 6 × 4
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2
## 2 79201064 2 3 2
## 3 79201118 1 2 3
## 4 79201275 2 2 2
## 5 79201481 2 3 3
## 6 79201556 2 3 3midiPISA1 verisinin oluşturulmasından sonra midiPISA2 verisi oluşturulur. Öncelikle midiPISA verisinden öğrenci id, okumaktan zevk alma ve okuma olası değer1 puanları değişkenleri seçilir. Ardından bu veri setinin ilk yedi satırı seçilir ve üçüncü satır silinir. Sonuç olarak altı satırlık bir midiPISA2 veri seti elde edilmiş olur.
#değişkenlerin seçimi
midiPISA2<- midiPISA %>% select(OGRENCIID,OKUMA_ZEVK,ODOKUMA1)
midiPISA2<-midiPISA2[1:7,] #veri setinin ilk 7 satırının seçilmesi
midiPISA2<-midiPISA2[-3,] #veri setinin 3. satırının çıkarılması
midiPISA2## # A tibble: 6 × 3
## OGRENCIID OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl>
## 1 79200768 -0.289 376.
## 2 79201064 0.604 512.
## 3 79201275 -1.15 393.
## 4 79201481 0.667 552.
## 5 79201556 0.357 441.
## 6 79201652 -0.0886 411.Elimizde bulunan midiPISA1 ve midiPISA2 veri setlerini kullanarak left_join() fonksiyonu ile birleştirme işlemi uygulanır.
## # A tibble: 6 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201118 1 2 3 NA NA
## 4 79201275 2 2 2 -1.15 393.
## 5 79201481 2 3 3 0.667 552.
## 6 79201556 2 3 3 0.357 441.Elde edilen çıktı incelendiğinde, midiPISA1 verisindeki tüm satırlar, midiPISA2 verisi ile eşleştirilmiş, “79201652”ıd numaralı öğrenci midiPISA1 de olmadığından hiç alınmamıştır. “79201118” ıd numaralı öğrenci ise midiPISA2 verisinde yer almadığında okumaktan zevk alma ve okuma olası değer1 değişkenleri “NA” olarak oluşturulmuştur.
3.3 right_join()
A %>% left_join(B) ile B verisindeki tüm satırlar, mümkün olduğunda A verisi ile eşleştirilerek (olmadığında “NA” verir), hem A hem de B den gelen sütunlar alınır.
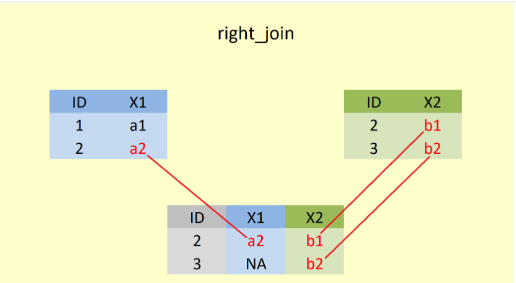
Şekil 2’de, right_join() fonksiyonu ile öncelikle X2 değişkenine ait tüm gözlemler alınmıştır. X1 değişkenine ait ID numarası “3” olan gözlem olmadığı için yeni veri setinde bu kısım kayıp veri(NA) olaraK girilmiştir. Burada da left_join() fonksiyonunda olduğu gibi birleştirme yapılacak iki veri setine ait ortak bir değişkenin (“ID”) olması önemlidir.
Örnek veri seti üzerinden açıklayalım:
## # A tibble: 6 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201275 2 2 2 -1.15 393.
## 4 79201481 2 3 3 0.667 552.
## 5 79201556 2 3 3 0.357 441.
## 6 79201652 NA NA NA -0.0886 411.Elde edilen çıktı incelendiğinde, midiPISA2 verisindeki tüm satırlar, midiPISA1 verisi ile eşleştirilmiş, “79201118”ıd numaralı öğrenci midiPISA2 de olmadığından oluşturulan veri setine hiç alınmamıştır.”79201652” ıd numaralı öğrenci ise midiPISA1 verisinde yer almadığında CINSIYET, ST097Q01TA,ST097Q01TA değişkenleri “NA” olarak oluşturulmuştur. Görüldüğü üzere left_join() ile right_join() fonksiyonları arasındaki fark eşleştirme öncesi temel alınacak ana veri setinin farklı olmasıdır. Fakat pratikte genellikle left_join() fonksiyonu kullanılır.
3.4 inner_join()
A %>% inner_join(B) ile sadece A ve B nin eşleşen satırlarını birleştirir. Yani hem A hem de B den gelen sütunları alır.

Şekil 3’te, inner_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak ortak olan satırlar yani 2. satır birleştirilir.
## # A tibble: 5 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201275 2 2 2 -1.15 393.
## 4 79201481 2 3 3 0.667 552.
## 5 79201556 2 3 3 0.357 441.“OGRENCIID” değişkeni ortak değişken olduğundan bu değişkene göre birleştirme işlemi yapılmış ve sadece her iki veri setinde yer alan öğrenciler seçilmiştir. Bu durumda “79201118” ve “79201652” id numaraya sahip öğrenciler birleştirme işleminden sonra yeni veri setinde yer almamıştır. Böylece yeni veri seti beş satırdan oluşmuştur.
3.5 full_join()
A %>% full_join(B) ile A ve B veri setinde yer alan tüm satırları birleştirir. Hem A hem de B den gelen sütunları alır.
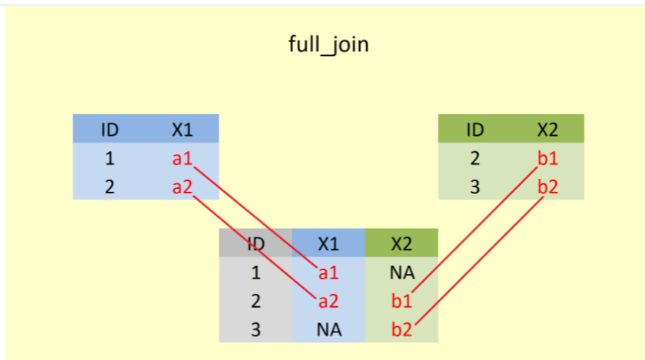
Şekil 4’te, full_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak iki veri setinde de yer alan tüm değişkenler birleştirilir.
## # A tibble: 7 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201118 1 2 3 NA NA
## 4 79201275 2 2 2 -1.15 393.
## 5 79201481 2 3 3 0.667 552.
## 6 79201556 2 3 3 0.357 441.
## 7 79201652 NA NA NA -0.0886 411.“OGRENCIID” değişkeni ortak değişken olduğundan bu değişkene göre birleştirme işlemi yapılmış ve her iki veri setinde yer alan tüm öğrenciler seçilmiştir. Bu durumda “79201118” ve “79201652” id numaraya sahip öğrenciler birleştirme işleminden sonra yeni veri setinde yer almıştır. Böylece yeni veri seti yedi satırdan oluşmuştur.
3.6 semi_join()
A %>% semi_join(B) ile A veri setinin B ile eşleşen satırları alınarak sadece A dan gelen sütunlar yeni veri setinde yer alır.
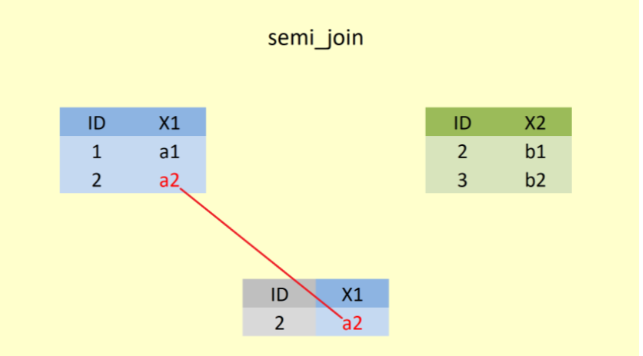
Şekil 5’te, semi_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak ortak olan satırlar yani 2. satır birleştirilir. Fakat yine sadece A veri setinde yer alan değişken ya da değişkenler alınır.
## # A tibble: 5 × 4
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2
## 2 79201064 2 3 2
## 3 79201275 2 2 2
## 4 79201481 2 3 3
## 5 79201556 2 3 3Çıktıda midiPISA1 verisinin midiPISA2 verisi ile eşleşen satırları ele alındığından “79201118” id numaralı öğrenci yeni veri setine dahil edilmemiştir. Ayrıca yeni veri setinde sadece midiPISA1 değişkeninde yer alan CINSIYET, ST097Q01TA, ST097Q02TA değişkenleri yer almıştır.
3.7 anti_join()
A %>% anti_join(B) ile A’nın B ile eşleşemeyen satırları alınarak yeni veri setinde sadece A’dan gelen sütunlara yer verilir.
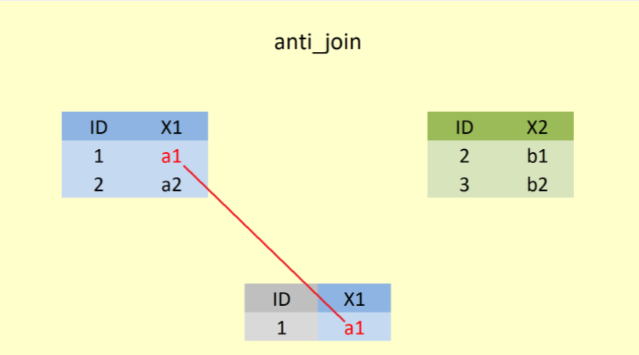
Şekil 6’da, anti_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak ortak olmayan satırlar yani sadece 1. satır ve A veri setindeki değişken (X1) alınmıştır.
## # A tibble: 1 × 4
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl>
## 1 79201118 1 2 3Çıktıda midiPISA1 verisinin midiPISA2 verisi ile eşleşmeyen satırları ele alındığından “79201118” id numaralı öğrenci yeni veri setine dahil edilmiştir. Ayrıca yeni veri setinde sadece midiPISA1 değişkeninde yer alan CINSIYET, ST097Q01TA, ST097Q02TA değişkenleri yer almıştır.
Not: Aynı değerleri içeren satırların olduğu sütunların eşleşmesi gerektiğini söyledik. Bunları birleştirme için aslında bir by = argümanı da kullanılır. Fakat birleştirme yapmak istediğimiz sütun/ların isimleri aynı olduğunda by = argümanını kullanmaya gerek kalmaz. Buraya kadar yapılan örnekler aşağıdaki gibi pipe operatörü kullanIlmadan da yapılabilir.
## # A tibble: 6 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201118 1 2 3 NA NA
## 4 79201275 2 2 2 -1.15 393.
## 5 79201481 2 3 3 0.667 552.
## 6 79201556 2 3 3 0.357 441.Elde edilen çıktı midiPISA1 %>% left_join(midiPISA2) fonksiyonu ile elde edilen çıktı ile aynıdır. Fakat değişken isimleri farklı olduğunda by argümanını kullanmak anlamlı olabilir. Şimdi bununla ilgili bir örnek yapalım. Öncelikle midiPISA2 veri setindeki “OGRENCIID” değişken ismini “STDNTID” olarak değiştirelim.
## # A tibble: 6 × 3
## STDNTID OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl>
## 1 79200768 -0.289 376.
## 2 79201064 0.604 512.
## 3 79201275 -1.15 393.
## 4 79201481 0.667 552.
## 5 79201556 0.357 441.
## 6 79201652 -0.0886 411.midiPISA3 verisi aslında midiPISA2 verisinin aynısıdır sadece tek bir değişkenin ismi değişmiştir.
Veri setinde eşleştirme yapılması istenilen değişkenin farklı adları olduğunda aşağıdaki kod kullanılabilir.
## # A tibble: 6 × 5
## OGRENCIID OKUMA_ZEVK.x ODOKUMA1.x OKUMA_ZEVK.y ODOKUMA1.y
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 -0.289 376. -0.289 376.
## 2 79201064 0.604 512. 0.604 512.
## 3 79201275 -1.15 393. -1.15 393.
## 4 79201481 0.667 552. 0.667 552.
## 5 79201556 0.357 441. 0.357 441.
## 6 79201652 -0.0886 411. -0.0886 411.Bu bölümde farklı veri setlerini birleştirme işlemlerine yer verilmiştir. Veri Düzenleme IV bölümünde veri setlerini farklı formatlara getirme ve analize hazırlık işlemlerine değinilecektir.