Bölüm 1 Veri Düzenleme I
1.1 dplyr paketi
Veri düzenlemede en sık kullanılan paketlerden biri olan dplyr paketi, içerdiği fonksiyonlar sayesinde veri düzenleme, sıralama, filtreleme, değişkenleri gruplama, yeni değişkenler oluşturma, seçme ve dönüştürme gibi işlemleri kolaylıkla yapabilmektedir. tidyverse evreninin bir parçası ve sözlük anlamı veri işleme grameri olan bu paket, veri düzenleme ve analizi sürecini oldukça kolaylaştırmaktadır. Veri manipülasyonunun grameri olarak bilinen paketin içerdiği fonksiyonlar, düzgün veri manipülasyonuna olanak tanımaktadır.
Paketin en sık kullanılan fonksiyonları; işlemleri bağlayan bağlama (pipe) %>%, istenilen değişkenlere göre yeni bir veri seti oluşturan select(), gözlemlerin seçilen degişkenlere göre yeniden sıralamaya yarayan arrange(), istenilen gözlemlerle yeni bir veri oluşturan filter(), yeni değişkenleri veri setine ekleyen mutate(), veride grup bazında işlem yapabilen group_by(), veriden özet istatistikleri elde eden summarise() ve verileri birleştirme işlemi yapabilen join() fonsiyonlarıdır. Veri düzenleme I bölümünde select(), filter(), arrange() ve mutate(), veri düzenleme II bölümünde veriyi üst düzeyde toplama işlemlerini gerçekleştiren count(), group_by() ve summarise() fonksiyonları, veri düzenleme III bölümünde birleştirme işlemleri yapan join() fonksiyonları açıklanmıştır. Veri düzenleme IV bölümünde ise veriyi R ortamına aktardıktan sonra verinin analize uygun formata getirilmesine ve tidyr paketi ile birlikte en sık kullanılan fonksiyonlara değinilmiştir.
Veri düzenlemede genellikle birden fazla değişkene ilişkin gözlemlerin yer aldığı veri setleri kullanılır. Pratiklik ve kolay anlaşılabilirlik adına PISA veri setinden değişken sayısının azaltılmasıyla oluşturulan midiPISA veri seti okutulmuş ve gerekli düzenlemeler yapılmıştır.
library(tidyverse) # paketin aktifleştirilmesi
load("data/midiPISA.rda") # çalışılacak veri setinin R ortamına aktarılması
midiPISA<- expss::drop_var_labs(midiPISA) # değişken etiketlerinin atılmasıtidyverse paketi aktif hâle getirildikten sonra oluşturulan data dosyasından midiPISA verisi yüklenir. PISA verileri OECD web adresinden SPSS formatında çekildiği için değişken etiketleri(label) ile birlikte gelmektedir. Bu etiket isimleri bazen R paketlerindeki fonksiyonlar ile birlikte çalışmamaktadır. Bu nedenle expss::drop_var_labs bu etiketlerin kaldırılmasını sağlar ve midiPISA veri seti üzerine kaydedilir.
Bir diğer alternatif ise değişken etiketlerini faktör düzeyi olarak kaydetmektir. Bu işlem aşağıdaki kodlarla sağlanabilir.
library(sjlabelled)
midiPISA <- midiPISA %>% mutate_if(is_labelled, as_factor)
# Faktor degiskenlere duzey atama amacıyla yazılan fonksiyon
levelsnames <- function(x){
levels(x) <- names(attr(x,"labels"))
x
}
# Yazılan fonkisyonun faktor degiskenlere uygulanması
midiPISA <-mutate_if(midiPISA,is.factor, levelsnames)1.2 pipe (%>%)
%>% simgesiyle ifade edilen pipe (bağlantı) operatörü, aynı veri tabanında yer alan bazı fonksiyonların birlikte tek bir kod hâlinde kullanılmasını sağlamaktadır. Bu durum fazla yazma yükünü ortadan kaldırarak kodu okunabilir kılmaktadır. Böylece veri daha pratik ve anlaşılır hâle gelerek kullanışlılığı artmaktadır. Aslında dplyr paketindeki tüm fonksiyonlar, daha az değişken oluşturmak amacıyla pipe operatörü (%>%) ile kullanılabilir.
%>% operatörü veri düzenleme işlemlerinde her zaman kullanışlı olduğundan sık tercih edilen bir operatördür. Kısa yolu windows için Ctrl+Shift+M, mac için Cmd+Shift+M’dir. Bu operatör magrittr paketinde yer aldığı için pipe operatörü kullanılırken paketin aktifliği kontrol edilmelidir.
%>% solundaki nesneye sağındaki fonksiyonu uygular. Yani pipe operatörünün solundaki öğeler, sağındaki fonksiyonun ilk argümanına iletilir. Fonksiyon ilk argümanı olan veriyi, pipe operatörünün solundan alır, kalan argümanlar fonksiyonun sağındadır.
library(dplyr) # paketin aktifleştirilmesi
library(magrittr) # paketin aktifleştirilmesi
x %>% f(y) = f(x, y)pipe operatörü ile zincirleme bağlama da yapılabilir. Fakat pipe, her bir fonksiyonu ayrı bir satırda bulundurulduğunda en net şekilde okunur. Bu nedenle her bir fonsiyonun ayrı yazılmasına dikkat edilmesi gerekir.
Gerçek bir veri seti üzerinden pipe operatörü ile ilgili bir örnek yapalım.
library(dplyr) # paketin aktifleştirilmesi
library(magrittr) # paketin aktifleştirilmesi (pipe operatörü için)
midiPISA %>%
filter(SINIF==9) %>% #sadece 9. sınıf öğrencilerinin seçilmesi
head(5) # ilk beş satırın görüntülenmesi## # A tibble: 5 × 16
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79201275 9 2 6 6 -1.15 2
## 2 79201481 9 2 4 4 0.667 3
## 3 79202354 9 2 4 4 -1.13 1
## 4 79202395 9 2 2 4 1.01 4
## 5 79203125 9 1 5 5 1.38 3
## # ℹ 9 more variables: ST097Q02TA <dbl>, ST097Q03TA <dbl>, ST097Q04TA <dbl>,
## # ST097Q05TA <dbl>, ODOKUMA1 <dbl>, ODOKUMA2 <dbl>, ODOKUMA3 <dbl>,
## # ODOKUMA4 <dbl>, ODOKUMA5 <dbl>Elde edilen çıktı incelendiğinde, midiPISA veri setinde 9. sınıf öğrencilerine ait gözlemlerin ilk beş satırı görüntülenmektedir. Bu örnekteki filter() fonksiyonu sadece sınıf düzeyi “9” olan öğrencilerin seçilmesini sağlamıştır. Bir sonraki başlıkta bu fonksiyon detaylı bir şekilde anlatılmıştır.
R nesne (object) yönelimli bir programlama dilidir. pipe operatörünün kullanımı ile oluşan çıktıdan yeni bir nesne oluşturmak istenirse, atama operatöru <- kullanılmalıdır. Bu şekilde oluşturulan yeni veri seti de çalışma alanına kaydedilmiş olur.
veri<- midiPISA %>%
filter(SINIF==9) %>% #sadece 9. sınıf öğrencilerinin seçilmesi
head(5) # ilk beş satırın görüntülemesi
veri # oluşturulan nesnenin okutulması## # A tibble: 5 × 16
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79201275 9 2 6 6 -1.15 2
## 2 79201481 9 2 4 4 0.667 3
## 3 79202354 9 2 4 4 -1.13 1
## 4 79202395 9 2 2 4 1.01 4
## 5 79203125 9 1 5 5 1.38 3
## # ℹ 9 more variables: ST097Q02TA <dbl>, ST097Q03TA <dbl>, ST097Q04TA <dbl>,
## # ST097Q05TA <dbl>, ODOKUMA1 <dbl>, ODOKUMA2 <dbl>, ODOKUMA3 <dbl>,
## # ODOKUMA4 <dbl>, ODOKUMA5 <dbl>Oluşturulan veri seti atama operatörü ile (<-) “veri” nesnesine atanmış ve “veri” adlı yeni bir veri seti oluşturulmuştur. Burada pipe operatörü ile birden fazla işlem birbirine bağlanmıştır. Fakat bağlama işlemleri ne kadar uzun olursa olsun <- operatörünün en başta yer alması gerektiği bilgisi unutulmamalıdır.
1.3 filter()
Satır bazında veri seçim işlemi yapmak amacıyla filter() fonksiyonu kullanılır. Böylece veri setindeki istenilen değişkenler filtrelenerek sadece bu gözlemlerden oluşan yeni bir veri seti elde edilir.
- filter() fonksiyonu kullanımı;
Buradaki filtreleme işlemi tek bir fonsiyon içinde ifade edildiği gibi pipe operatörü ile de kullanılabilir.
- filter() fonksiyonunun pipe ile kullanımı;
filter() fonksiyonu ek olarak mantıksal operatörleri kullanarak koşulları test ettiğinden bu operatörlerin bilinmesi oldukça önemlidir. En sık kullanılan mantıksal operatörler eşittir “==”, eşit değil “!=”, büyüktür “>”, küçüktür “=<”, büyük eşittir “>=” olup bunların kombinasyonları da kullanılabilir. Çünkü filter() fonksiyonu birden fazla mantıksal testi aynı anda çalıştırarak istenilen satır ya da gözlemin seçilmesini sağlar.
filter() fonksyonuna geçmeden önce mantıksal operatörler ile koşulların test edildiği örneklere yer verelim:
Örneğin x nesnesi 8-2*3+1 işlemi olarak tanımlansın ve x’in 3’e eşit olup olmadığı test edelim.
## [1] TRUEÇıktıda yer alan “TRUE”, sonucun “3” olduğunu yani sonucun doğruluğunu göstermektedir.
y nesnesi olarak tanımlanan işlemin 3’e eşit olmadığı varsayılsın. Bu işlemin sonucu ise şüphesiz “FALSE” olacaktır. Çünkü yukarıdaki örnekte işlem sonucunun “3” olduğu bulunmuştu.
## [1] FALSEÇıktıda TRUE, FALSE ve NA değerleri yer alabilir. filter() fonksiyonu koşulun sağlandığı satırları seçer. & (ve), | (veya) , !(değil) operatörleri de filter() fonksiyonu ile oldukça sık kullanılır.
filter() fonksiyonu ile midiPISA veri setini kullanarak sadece kız öğrencilerden oluşan yeni bir veri seti oluşturmaya çalışalım. Öncelikle cinsiyet ile ilgili bilgiyi içeren CINSIYET adlı değişken belirlenir. Bu değişkende kız öğrenciler “1” ve erkek öğrenciler “2” olarak kodlanmıştır.
kiz <- filter(midiPISA, CINSIYET ==1) %>% # CINSIYETe göre filtreleme
head(5) #ilk beş satırın görüntülenmesi
kiz## # A tibble: 5 × 16
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79201118 10 1 1 2 0.638 2
## 2 79201652 10 1 5 5 -0.0886 3
## 3 79202179 10 1 1 4 1.22 3
## 4 79202313 10 1 1 5 1.58 4
## 5 79202360 10 1 4 1 1.60 2
## # ℹ 9 more variables: ST097Q02TA <dbl>, ST097Q03TA <dbl>, ST097Q04TA <dbl>,
## # ST097Q05TA <dbl>, ODOKUMA1 <dbl>, ODOKUMA2 <dbl>, ODOKUMA3 <dbl>,
## # ODOKUMA4 <dbl>, ODOKUMA5 <dbl>Görüldüğü gibi bu fonksiyon midiPISA veri seti ile beraber bir mantıksal test ifadesi içerir. Bu mantıksal test ifadesi “CINSIYET == 1”, yani kız öğrenciler şeklinde ifade edilmiştir. Böylece bu mantıksal kontrole dayanarak oluşan “kiz” isimli veri setinde “CINSIYET” değişkeninin sadece “1” olarak kodlandığı gözlemler seçilir.
midiPISA verisinde Anne_Egitim anne eğitim düzeyini, Baba_Egitim baba eğitim düzeyini belirten değişkenlerdir. Belirtilen değişkenlerde lisansüstü mezun olma durumu “6” kodu ile belirtilmektedir. Anne eğitim düzeyi lisansüstü olan öğrencilerin seçilmesi;
## # A tibble: 5 × 16
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79201275 9 2 6 6 -1.15 2
## 2 79202343 11 2 6 6 -0.112 1
## 3 79203553 10 1 6 5 1.19 4
## 4 79204714 10 2 6 4 0.338 3
## 5 79200971 10 2 6 5 -0.167 3
## # ℹ 9 more variables: ST097Q02TA <dbl>, ST097Q03TA <dbl>, ST097Q04TA <dbl>,
## # ST097Q05TA <dbl>, ODOKUMA1 <dbl>, ODOKUMA2 <dbl>, ODOKUMA3 <dbl>,
## # ODOKUMA4 <dbl>, ODOKUMA5 <dbl>Çıktıda anne eğitim düzeyi sadece lisansüstü(6) olan öğrencilere ait verilerin ilk beş satırı görüntülenmektedir.
- Anne eğitim düzeyi ve baba eğitim düzeyi lisansüstü olan öğrencilerin seçilmesi;
## # A tibble: 5 × 16
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79201275 9 2 6 6 -1.15 2
## 2 79202343 11 2 6 6 -0.112 1
## 3 79201796 10 2 6 6 0.842 4
## 4 79202928 10 2 6 6 -0.112 4
## 5 79200826 10 1 6 6 2.61 3
## # ℹ 9 more variables: ST097Q02TA <dbl>, ST097Q03TA <dbl>, ST097Q04TA <dbl>,
## # ST097Q05TA <dbl>, ODOKUMA1 <dbl>, ODOKUMA2 <dbl>, ODOKUMA3 <dbl>,
## # ODOKUMA4 <dbl>, ODOKUMA5 <dbl>Çıktıda hem anne eğitim düzeyi hem de baba eğitim düzeyi lisansüstü(6) olan öğrencilere ait verilerin ilk beş satırı görüntülenmektedir.
- Anne eğitim düzeyi veya baba eğitim düzeyi lisansüstü olan öğrencilerin seçilmesi;
## # A tibble: 5 × 16
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79201275 9 2 6 6 -1.15 2
## 2 79201556 10 2 4 6 0.357 3
## 3 79202343 11 2 6 6 -0.112 1
## 4 79203553 10 1 6 5 1.19 4
## 5 79203843 10 2 5 6 0.780 4
## # ℹ 9 more variables: ST097Q02TA <dbl>, ST097Q03TA <dbl>, ST097Q04TA <dbl>,
## # ST097Q05TA <dbl>, ODOKUMA1 <dbl>, ODOKUMA2 <dbl>, ODOKUMA3 <dbl>,
## # ODOKUMA4 <dbl>, ODOKUMA5 <dbl>Çıktıda anne eğitim düzeyi veya baba eğitim düzeyi lisansüstü(6) olan öğrencilere ait verilerin ilk beş satırı görüntülenmektedir.
Özellikle büyük veriler ile çalışıldığında filter() fonksiyonu, sadece istediğimiz gözlemlerden oluşan yeni bir veri seti oluşturması açısından önemli bir pratiklik sağlar. Tabi ki yeni oluşan veri setini bir nesneye atayarak çalışma alanına kaydetmeyi unutmamak gerekir.
1.4 select()
Veri setinden sütun bazında seçim yapmak için select() fonksiyonu kullanılabilir. Bu fonksiyonun kullanımı;
select() fonksiyonu dplyr içindeki diğer fonksiyonlarla da sıklıkla kullanılır. Örneğin pipe operatörü ile kullanımı;
midiPISA veri seti ile select() fonksiyonunu kullanarak yeni bir veri seti oluşturalım.
## # A tibble: 5 × 4
## OGRENCIID ST097Q01TA ST097Q04TA OKUMA_ZEVK
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 1 1 -0.289
## 2 79201064 3 3 0.604
## 3 79201118 2 3 0.638
## 4 79201275 2 1 -1.15
## 5 79201481 3 3 0.667Görüldüğü üzere dört değişkenden oluşan yeni bir veri seti oluşturulmuştur.select() fonksiyonu, orijinal veri setinde herhangi bir değişikliğe yol açmaz. Bu nedenle seçim yapılan değişkenlerden oluşan yeni veri setini ayrı bir R nesnesine atayarak kaydetmek gereklidir.
Bazen özellikle büyük veri setleri ile çalışıldığında, değişkenlerin tek tek isimlerini yazarak seçmek oldukça vakit alabilir. O nedenle select() fonksiyonu ile belirli bir aralıkta yer alan değişkenler iki nokta : operatörü ile seçilebilirken, bu aralıkta dâhil edilmek istenmeyen değişkenler kısa çizgi - operatörü ile ifade edilebilir.
midiPISA %>%
select(OGRENCIID:ST097Q04TA,-CINSIYET) %>% # sütun bazında değişken ekleme ve çıkarma
head(5) #ilk beş satırın görüntülenmesi## # A tibble: 5 × 9
## OGRENCIID SINIF Anne_Egitim Baba_Egitim OKUMA_ZEVK ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 10 2 2 -0.289 1 2
## 2 79201064 10 2 2 0.604 3 2
## 3 79201118 10 1 2 0.638 2 3
## 4 79201275 9 6 6 -1.15 2 2
## 5 79201481 9 4 4 0.667 3 3
## # ℹ 2 more variables: ST097Q03TA <dbl>, ST097Q04TA <dbl>Elde edilen çıktı incelendiğinde, OGRENCIID, SINIF, Anne_Egitim, Baba_Egitim,OKUMA_ZEVK,ST097Q01TA, ST097Q02TA, ST097Q03TA ve ST097Q04TA değişkenleri seçilmiştir. Bu aralıkta yer alan CINSIYET değişkeni ise seçilmemiştir.
Sadece dplyr paketi içindeki select() fonksiyonu içinde çalışan ve daha detaylı seçimler yapma imkânı sunan bir grup yardımcı fonksiyon içermektedir. Bunlardan en sık kullanılanlar; starts_with(), contains(), matches(), num_range() fonksiyonlarıdır. Burada dikkat edilmesi gereken nokta bu fonksiyonların içindeki ifadenin çift tırnak (“ “) ile beraber kullanılması gerekliliğidir.
- starts_with() sadece
select()fonksiyonu içinde çalışan ve değişken seçme işlemini kolaylaştıran yardımcı bir fonksiyondur. Örneğin ST097 ile başlayan degişkenlerstarts_with()fonksiyonu ile seçilebilir.
## # A tibble: 5 × 5
## ST097Q01TA ST097Q02TA ST097Q03TA ST097Q04TA ST097Q05TA
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 2 1 1 1
## 2 3 2 3 3 3
## 3 2 3 3 3 3
## 4 2 2 3 1 1
## 5 3 3 4 3 1Elde edilen çıktı incelendiğinde “ST097” ile başlayan beş değişkenin seçildiği yeni veri setine ait ilk beş satır görülmektedir.
- ends_with() benzer şekilde TA ile biten değişkenler seçilmek istendiğinde kullanılır.
## # A tibble: 5 × 5
## ST097Q01TA ST097Q02TA ST097Q03TA ST097Q04TA ST097Q05TA
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 2 1 1 1
## 2 3 2 3 3 3
## 3 2 3 3 3 3
## 4 2 2 3 1 1
## 5 3 3 4 3 1Elde edilen çıktı incelendiğinde “TA” ile biten beş değişkenin seçildiği görülmektedir.
- contains() yine benzer şekilde içinde belli harfler geçen değişkenler seçilmek istendiğinde kullanılır. Örneğin içinde OD geçen değişkenlerin seçilmesi;
## # A tibble: 5 × 5
## ODOKUMA1 ODOKUMA2 ODOKUMA3 ODOKUMA4 ODOKUMA5
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 376. 418. 421. 414. 434.
## 2 512. 473. 564. 485. 500.
## 3 396. 414. 423. 452. 392.
## 4 393. 429. 365. 383. 379.
## 5 552. 570. 563. 531. 532.Elde edilen çıktıya göre içinde “OD” geçen beş okuma olası değerin yer aldığı değişkenler görülmektedir.
- matches() içinde 02 geçen değişkenlerin seçilmesinde kullanılır.
## # A tibble: 5 × 1
## ST097Q02TA
## <dbl>
## 1 2
## 2 2
## 3 3
## 4 2
## 5 3Elde edilen çıktıya göre içinde “02” geçen bir değişken görülmektedir.
- num_range() fonksiyonu ise ardışık ilerleyen değişkenlerin seçilmesinde kullanılır. midiPISA veri setinde okuma ile ilgili beş olası değer bulunduğundan sadece 1 ve 3 arasındakiler seçilmiştir ve ilk beş gözleme ait değerler istenmiştir. Tabi ki bu örneğimizde değişken sayısı az olduğundan bu seçim çok anlamlı görünmeyebilir fakat özellikle büyük verilerle çalışılırken bu seçim işlemi oldukça pratik olabilmektedir.
## # A tibble: 5 × 3
## ODOKUMA1 ODOKUMA2 ODOKUMA3
## <dbl> <dbl> <dbl>
## 1 376. 418. 421.
## 2 512. 473. 564.
## 3 396. 414. 423.
## 4 393. 429. 365.
## 5 552. 570. 563.Okuma puanı olası değerleri veri setinde sıralı bir şekilde yer aldığından, bu değerlerden ilk üçü num_range() fonksiyonu kullanılarak seçilmiştir.
Farklı fonksiyonlar ve aynı anda mantıksal operatörler kullanılarak da seçim işlemleri gerçekleştirilebilir. Örneğin veya | operatörü kullanılarak seçim yapılabilir.
midiPISA veri setinde “OD” içeren veya içinde “1” rakamı geçen değişken seçimi;
## # A tibble: 5 × 6
## ODOKUMA1 ODOKUMA2 ODOKUMA3 ODOKUMA4 ODOKUMA5 ST097Q01TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 376. 418. 421. 414. 434. 1
## 2 512. 473. 564. 485. 500. 3
## 3 396. 414. 423. 452. 392. 2
## 4 393. 429. 365. 383. 379. 2
## 5 552. 570. 563. 531. 532. 3Elde edilen çıktı incelendiğinde, içinde “OD” veya “1” geçen toplam altı değişken olduğu görülmektedir. & operatörünün kullanımı da oldukça fazladır.
midiPISA veri setinde A harfini içeren ve içinde “2” rakamı olan değişkenlerin seçimi için;
## # A tibble: 5 × 2
## ST097Q02TA ODOKUMA2
## <dbl> <dbl>
## 1 2 418.
## 2 2 473.
## 3 3 414.
## 4 2 429.
## 5 3 570.Çıktı incelendiğinde “O” harfini içeren ve içinde “2” rakamı olan ST097Q02TA ve ODOKUMA2 değişkenleri olmak üzere iki değişken olduğu görülmektedir.
Hariç tutmak ve veri setinden çıkarmak amacıyla - operatörü kullanılabilir. “O” harfini içermeyen ve içinde “0” rakamı olmayan değişkenlerin seçimi için;
## # A tibble: 5 × 4
## SINIF CINSIYET Anne_Egitim Baba_Egitim
## <dbl> <dbl> <dbl> <dbl>
## 1 10 2 2 2
## 2 10 2 2 2
## 3 10 1 1 2
## 4 9 2 6 6
## 5 9 2 4 4Elde edilen çıktı incelendiğinde, midiPISA veri setinden “O” içermeyen ve içinde “0” rakamı olmayan SINIF, CINSIYET, Anne_Egitim ve Baba_Egitim değişkenleri seçilmiştir.
1.5 arrange()
arrange() fonksiyonu satırları/gözlemleri sıralamak amacıyla kullanılır. Sıralama işlemini alfabetik sıralamaya göre yapar. Fakat ek bir fonksiyon yazıldığında büyüklük sırasına göre de sıralama yapar. Böylece veri seti istenilen kritere göre sıralanarak değişkenler arasındaki ilişki daha pratik bir şekilde görülebilir. arrange() fonksiyonunun kullanımı oldukça kolaydır; fonksiyonun içine veri setinin adını ve sıralama için kullanılacak değişkeni yazmak yeterli olur.
- arrange() fonksiyonunun kullanımı;
arrange()fonksiyonunun pipe operatörü %>% ile kullanımı;
Örnek veri seti üzerinden dört değişken seçip yeni bir veri setine (df) atayarak kaydedelim.
## # A tibble: 6 × 4
## OGRENCIID ST097Q01TA ST097Q04TA OKUMA_ZEVK
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 1 1 -0.289
## 2 79201064 3 3 0.604
## 3 79201118 2 3 0.638
## 4 79201275 2 1 -1.15
## 5 79201481 3 3 0.667
## 6 79201556 3 2 0.357- Yeni oluşan df veri setini OKUMA_ZEVK(okumaktan zevk alma) puanlarına göre sıralayalım.
## # A tibble: 5 × 4
## OGRENCIID ST097Q01TA ST097Q04TA OKUMA_ZEVK
## <dbl> <dbl> <dbl> <dbl>
## 1 79204460 1 1 -2.73
## 2 79201124 1 1 -2.71
## 3 79204401 3 2 -2.71
## 4 79206724 1 3 -2.71
## 5 79204126 4 4 -2.71Elde edilen çıktı incelendiğinde, arrange() fonksiyonu ile öğrencilerden elde edilen gözlemler okumaktan zevk alma puanlarına göre küçükten büyüğe sıralanmıştır. Çünkü paket içerisinde yer alan fonksiyon sıralamayı önceden tanımlı/default olarak küçükten büyüğe yapar. Fakat bu gözlemler, büyükten küçüğe sıralanmak istendiğinde ek olarak arrenge() fonksiyonu içine desc() fonksiyonu yazılır.
## # A tibble: 5 × 4
## OGRENCIID ST097Q01TA ST097Q04TA OKUMA_ZEVK
## <dbl> <dbl> <dbl> <dbl>
## 1 79206987 3 2 2.66
## 2 79204432 3 3 2.66
## 3 79206337 4 4 2.66
## 4 79203300 3 2 2.61
## 5 79205358 4 2 2.611.5.1 select() ve arrange() fonksiyonları
Yeni bir veri seti tanımlanmadan da pipe operatörü kullanılarak tek bir kod hâlinde sıralama yapılabilir.
midiPISA %>%
select(OGRENCIID,ST097Q01TA,ST097Q04TA,OKUMA_ZEVK) %>% #değişkenlerin seçimi
arrange(OKUMA_ZEVK)%>% # değişkendeki gözlemleri sıralama
head(6) #ilk 6 satırın görüntülenmesi## # A tibble: 6 × 4
## OGRENCIID ST097Q01TA ST097Q04TA OKUMA_ZEVK
## <dbl> <dbl> <dbl> <dbl>
## 1 79204460 1 1 -2.73
## 2 79201124 1 1 -2.71
## 3 79204401 3 2 -2.71
## 4 79206724 1 3 -2.71
## 5 79204126 4 4 -2.71
## 6 79205685 3 3 -2.711.5.2 rename()
Veri setinden istenilen değişkenler seçilerek yeni bir veri seti oluşturulmak istendiğinde seçilen değişkenlerin de ismini değiştirmek isteyebiliriz. Bu durumda rename() fonksiyonu (yeni ad=eski ad) şeklinde kullanılabilir.
midiPISA %>%
select(ODOKUMA1,ODOKUMA2)%>%
rename(okumapuan1=ODOKUMA1,okumapuan2=ODOKUMA2) %>%
head(3) ## # A tibble: 3 × 2
## okumapuan1 okumapuan2
## <dbl> <dbl>
## 1 376. 418.
## 2 512. 473.
## 3 396. 414.Görüldüğü üzere veri setinden seçilen ODOKUMA1 ve ODOKUMA2 sütunlarının isimleri okumapuan1 ve okumapuan2 olarak değiştirilmiştir.
select() fonksiyonu içinde değişken seçimi sırasında da değişken adı değişimi yapılabilir. Örnekte midiPISA veri setinden dört değişken seçilerek oluşturulan yeni veri setinde okuma becerileri olası değerleri 1 in yer aldığı ODOKUMA1 değişkeninin adı okumapuan1 olarak değiştirilip seçilebilir.
## # A tibble: 3 × 4
## OGRENCIID ST097Q02TA ST097Q03TA okumapuan1
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 376.
## 2 79201064 2 3 512.
## 3 79201118 3 3 396.Yeni seçilen veri setinde sadece ODOKUMA1 değişkeninin ismi okumapuan1 olarak değiştirilmiştir. Diğer üç değişkenin isminin aynı kaldığı görülmektedir.
1.6 mutate()
mutate() fonksiyonu ile veri setine yeni değişkenler eklenirken mevcut değişkenler de korunur ancak transmutate() fonksiyonu ile eski değişkenler veri setiden çıkarılarak yeni değişken eklenir.
mutate() fonksiyonunun kullanımı;
Örneğin ST097 ile başlayan maddelerden yeni bir veri seti oluşturulup, bu veri setine toplam puan eklenebilir. Aşağıdaki örnekte ST097 ile başlayan maddeler seçilmiş ve seçilen beş maddenin toplamı ayrı bir değişken olarak eklenmiştir. Oluşturulan bu toplam puan değişkeni ve beş madde zevk adlı yeni bir veri seti olarak eklenmiştr.
zevk<- select(midiPISA, starts_with("ST097"))
zevk%>%
mutate(toplam =ST097Q01TA+ST097Q02TA+ST097Q03TA+ST097Q04TA+ST097Q05TA) %>%
head(3) ## # A tibble: 3 × 6
## ST097Q01TA ST097Q02TA ST097Q03TA ST097Q04TA ST097Q05TA toplam
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 2 1 1 1 6
## 2 3 2 3 3 3 14
## 3 2 3 3 3 3 14Bu örnekte değişken değerleri + ile toplanacağı gibi rowSums() fonksiyonu ile de aşağıdaki gibi toplanabilir. Bu bize özellikle çok fazla maddenin yer aldığı ölçeklerde toplam puan almada pratiklik sağlar. Örnekte kullanılan across(), aynı dönüşümü birden fazla sütuna uygulamayı kolaylaştırarak summarise() ve mutate() gibi fonkisyonların içinde select() ile aynı işlevi kullanmanıza olanak tanır.
## # A tibble: 3 × 6
## ST097Q01TA ST097Q02TA ST097Q03TA ST097Q04TA ST097Q05TA toplam
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 2 1 1 1 6
## 2 3 2 3 3 3 14
## 3 2 3 3 3 3 14Ayrıca yeni değişken üretiminde sadece toplama değil istenen her türlü işlem yapılabilir. Yeni eklenecek yerler .before ya da .after argümanları ile düzenlenebilir.
midiPISA veri setinde yer alan ST097Q01TA, ST097Q02TA, ST097Q03TA, ST097Q04TA ve ST097Q05TA maddelerinden elde edilen toplam puan değişkeni “ST097Q01TA” değişkeninin hemen önüne eklenir.
## # A tibble: 3 × 6
## toplam ST097Q01TA ST097Q02TA ST097Q03TA ST097Q04TA ST097Q05TA
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 6 1 2 1 1 1
## 2 14 3 2 3 3 3
## 3 14 2 3 3 3 3Ek olarak mutate() fonksiyonu ile birden fazla değişken de eklenebilir. Yani tek bir kod ile birden fazla yeni değişken üretilebilir.
1.6.1 transmute()
transmute() fonksiyonu kullanılarak yeni değişken oluşturulduğunda, işlemde kullanılan değişkenler veri setinden çıkarılır, sadece yeni oluşturulan değişken veri setine eklenir.
## # A tibble: 2 × 1
## toplam
## <dbl>
## 1 6
## 2 141.6.2 ifelse()
ifelse() programlama dillerinde sıklıkla kullanılan koşullu önermelerden biridir. ifelse() fonksiyonunun kullanımı;
Bir örnek üzerinde ifelse() fonksiyonunu açıklayalım. Öncelikle x nesnesini aşağıdaki gibi tamsayılardan oluşturalım ve ifelse() fonksiyonu sayesinde sıfırdan küçük olanlar negatif, büyük olanlar pozitif olacak şekilde tanımlansın.
## [1] "Negatif" "Pozitif" "Negatif" "Negatif" "Pozitif"Çıktıda görüldüğü üzere tamsayıların negatif veya pozitif olduğu sırasıyla belirlenmiştir.
midiPISA verisindeki sınıf düzeyi değişkeni kullanılarak bir örnek yapalım. Sınıf değişkeninde 7., 8., 9., 10., 11. ve 12.sınıf öğrencileri yer almaktadır ve aşağıda görüldüğü gibi ortaokul düzeyinde oldukça az sayıda öğrenci bulunmaktadır.
##
## 7 8 9 10 11 12
## 3 19 1295 5360 207 6SINIF değişkenini kullanarak ortaokul ve lise olmak üzere iki düzeyli OKUL adlı bir değişken oluşturalım. Oluşturulacak yeni değişken “ortaokul” ve “lise” olmak üzere iki kategorili olup 7. ve 8. sınıflar ortaokul diğer sınıflar ise lise olarak kodlanmıştır.
Okultur <- midiPISA %>%
select(1:5) %>% #ilk beş değişkenin seçimi
mutate(okul = ifelse(SINIF == 7 | SINIF == 8,
"Ortaokul", "Lise")) %>% # okul değişkeninin veri setine eklenmesi
arrange(SINIF) # veri setinin SINIF değişkenine göre sıralanması
tail(Okultur)## # A tibble: 6 × 6
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim okul
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 79203092 12 1 0 1 Lise
## 2 79204140 12 2 0 1 Lise
## 3 79200174 12 1 5 5 Lise
## 4 79206519 12 1 0 0 Lise
## 5 79205173 12 1 5 5 Lise
## 6 79201478 12 1 0 1 LiseElde edilen çıktıda son üç satırdaki sınıf düzeyleri 12 olduğundan okul değişkeninin son üç satırı da lise olarak kategorilendirilmiştir.
## # A tibble: 3 × 6
## OGRENCIID SINIF CINSIYET Anne_Egitim Baba_Egitim okul
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 79204097 7 1 2 2 Ortaokul
## 2 79207110 7 2 6 1 Ortaokul
## 3 79202600 7 2 NA NA OrtaokulElde edilen çıktıda ilk üç satırdaki sınıf düzeyleri 7 olduğundan okul değişkeninin ilk üç satırı da ortaokul olarak kategorilendirilmiştir.
1.6.3 case_when()
case_when() fonksiyonu çoklu ifelse() kullanımı ile benzer işlevi sağlar. case_when() birden fazla koşula dayalı karşılaştırmalarda yeni bir değişken oluşturmak amacıyla kullanılır.
- ODOKUMA1 düzeyine ilişikin betimsel istatistikler;
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 175.6 402.6 463.4 464.2 525.7 771.5ODOKUMA1 değişkeninin kategorik hale getirilmesinde çeyreklik puanları kullanılmıştır.
v1 <- midiPISA %>%
mutate(ODOKUMA1_kategorik =
case_when(
ODOKUMA1 <= 402.6 ~ "dusuk",
ODOKUMA1 > 402.6 & ODOKUMA1 < 525.7 ~ "orta",
ODOKUMA1 >=525.7 ~ "yuksek" )) %>%
select(ODOKUMA1,ODOKUMA1_kategorik)
head(v1)## # A tibble: 6 × 2
## ODOKUMA1 ODOKUMA1_kategorik
## <dbl> <chr>
## 1 376. dusuk
## 2 512. orta
## 3 396. dusuk
## 4 393. dusuk
## 5 552. yuksek
## 6 441. ortaOkuma puanı 402.6’dan küçük olanlar düşük, 402.6 ile 525.7 arasında olanlar orta, 525.7 den büyük olanlar ise yüksek olarak kategorilendirilmiştir. Oluşturulan ODOKUMA1_kategorik adlı yeni değişken ile okuma puanı olası değerlerinin yer aldığı ODOKUMA1 değişkeninden oluşan yeni veri seti v1 olarak çalışma alanına kaydedilmiştir. head() fonksiyonu ile v1 veri setinin ilk altı satırı görüntülenmektedir.
- Oluşturulan yeni ODOKUMA1 kategorik degişkeninindeki düzeylerin veri setinde nasıl dağıldığını inceleyelim.
## # A tibble: 3 × 2
## ODOKUMA1_kategorik f
## <chr> <int>
## 1 dusuk 1724
## 2 orta 3443
## 3 yuksek 1723Elde edilen çıktıda her bir kategoriye ait frekans değerleri yer almaktadır.
Bu bölümde dplyr paketi ve bu pakette yer alan beş temel veri düzenleme fonksiyonu açıklanmıştır.
Bölüm 2 Veri Düzenleme II
Veri düzenlemenin diğer bir aşaması ise veriyi üst düzeyde toplama işlemleridir. Bu işlemlerden en sık kullanılanlar; count(), grup_by(), summarise(), summarise_all(), summarise_if(), summarise_at(),across(), top_n() fonksiyonlarıdır. Yine bu fonksiyonlar dplyr paketi içerisinde yer almakatadır. Sırasıyla örneklerle bu fonksiyonları inceleyelim.
2.1 count() fonksiyonu
count() fonksiyonu frekans tablosu oluşturmak için kullanılmaktadır. Yine pipe operatörü ile birlikte sıklıkla kullanılmaktadır.
count()fonksiyonunun pipe ile kullanımı:
Görüldüğü üzere fonksiyonun içine değişken ismini yazmak yeterlidir. Örnek veri seti üzerinden fonksiyonun kullanımını inceleyelim.
## # A tibble: 1 × 1
## n
## <int>
## 1 6890Elde edilen çıktıya göre midiPSA verisinde 6890(n) gözlem olduğu görülmektedir. Fakat sadece tek bir değişkene göre dağılım incelenmek istenirse fonksiyonun içine değişken ismi yazılmalıdır.
## # A tibble: 2 × 2
## CINSIYET n
## <dbl> <int>
## 1 1 3396
## 2 2 3494Çıktıda cinsiyet değişkenine göre frekans tablosu yer almaktadır. Kız(1) öğrencilerin sayısı 3396, erkek öğrencilerin sayısı 3494 olduğu görülmektedir. Ayrıca cinsiyete göre dağılımlar sıralanmak istenebilir. Bu durumda sort argümanı ile kullanılabilir.
## # A tibble: 2 × 2
## CINSIYET n
## <dbl> <int>
## 1 2 3494
## 2 1 3396Elde edilen çıktıda sort argümanı yardımıyla frekans tablosundaki değerlerin sıralandığı görülmektedir. Şimdi bu veri setini kullanarak öğrencilerin SINIF ve CINSIYET değişkenlerine göre dağılımını sıralama argümanını kullanarak inceleyelim.
# CINSIYET ve SINIF değişkenlerine göre dağılımın sıralanması
midiPISA %>% count(CINSIYET,SINIF, sort=TRUE) ## # A tibble: 12 × 3
## CINSIYET SINIF n
## <dbl> <dbl> <int>
## 1 1 10 2707
## 2 2 10 2653
## 3 2 9 747
## 4 1 9 548
## 5 1 11 124
## 6 2 11 83
## 7 1 8 11
## 8 2 8 8
## 9 1 12 5
## 10 2 7 2
## 11 1 7 1
## 12 2 12 1Elde edilen çıktıda sınıf düzeyi (SINIF), cinsiyet (CINSIYET) ve frekansların (n) yer aldığı üç sütunun olduğu görülmektedir. “sort=TRUE” yardımıyla n sütunundaki değerler büyükten küçüğe sıralanarak verilmiştir. CINSIYET değişkeni iki kategori, SINIF değişkeni altı kategoriden oluştuğundan toplam 12 satır yer almaktadır. Frekansı en yüksek olan grup (n=2707) 10. sınıfa ait kız öğrencilerdir(1).
Gruplandırılmış veride bellirli bir değişkene ilişkin toplam almak istenirse count() fonksiyonunun wt() argümanı kullanılabilir.
# CINSIYET değişkenine göre gruplandırılmış veride SINIF değişkenine göre toplam frekans sayısı
midiPISA %>% count(SINIF, wt=CINSIYET, sort=TRUE)## # A tibble: 6 × 2
## SINIF n
## <dbl> <dbl>
## 1 10 8013
## 2 9 2042
## 3 11 290
## 4 8 27
## 5 12 7
## 6 7 5Elde edile çıktı incelendiğinde sınıf değişkenine göre büyükten küçüğe olacak şekilde frekans tablosu oluşturulduğunda CINSIYET dğişkenine göre toplam alınmıştır. Örneğin 10. sınıflarda 8013 kız veya erkek öğrencinin yer aldığı görülmektedir.
2.2 summarise()/summarize()
summarise() fonksiyonu tek satırda veri setini özetleyerek yeni bir veri seti oluşturan fonksiyondur. Yani seçilen sütunlar için her satırı kullanarak özet istatistikleri hesaplar. Örneğin; min() minumum değer, max() maksimum değer, mean() ortalama değer, median() ortanca, quantile() q. yuzdelik, sd() standart sapma, var() varyans, diff(range())değiskenlik, first() ilk eleman, last() son eleman, nth() n. eleman n() toplam eleman sayısı, n_distinct() farklı değerlerin sayısı hesaplanabilir.
midiPISA veri setinde yer alan okuma başarısı için hesaplanan olası puan değerlerinden (plausible value) ilki kullanılmıştır. Burada okuma puanlarının ortalaması hesaplanabilir.
## # A tibble: 1 × 1
## `mean(ODOKUMA1)`
## <dbl>
## 1 464.midiPISA verisinde yer alan okumapuanı1 değerlerinin ortalaması 464.23 bulunmuştur. Görüldüğü üzere summarise() fonksiyonu içinde isimlendirme yapılamaz, oluşan veri setinde isimlendirme yapmak için:
# ortalamanın "ortalama" sütun ismi ile hesaplanması
midiPISA %>%
summarise(ortalama=mean(ODOKUMA1)) ## # A tibble: 1 × 1
## ortalama
## <dbl>
## 1 464.Genellikle bir veri setinde özet bilgiler elde etmek için birden fazla özetleyici fonksiyon kullanılmak istenebilir. Örneğin bir veri setindeki değişkenlerin hem ortalaması, hem standart sapması hem de minimum, maksimum değerleri hesaplanmak istenebilir. Bu durumda aşağıdaki örnekte olduğu gibi bu fonksiyonlar “,” kullanılarak art arda yazılabilir.
midiPISA %>%
summarise(n = n(),
ortalama=mean(ODOKUMA1),
sd=sd(ODOKUMA1),
min=min(ODOKUMA1),
max=max(ODOKUMA1))## # A tibble: 1 × 5
## n ortalama sd min max
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 6890 464. 87.8 176. 772.Elde edilen çıktıda sırasıyla, frekans(n), ortalama(mean), standart sapma(sd), minimum (min) ve maksimum (max) değerleri yer almaktadır.
2.3 summarise() ve group_by()
summarise() fonksiyonu gruplandırılmamış bir veri setinde, tüm satırlardan özet istatistik bilgileri hesaplamıştır. Bu bilgiler, veri setinde yer alan alt gruplar için ise ayrı ayrı group_by() fonksiyonu ile hesaplanabilir. group_by() dan sonra kullanılan fonksiyonlar her grup için ayrı ayrı hesaplanama yapar ve bu fonksiyon içinde sürekli değişken kullanılmaz.
- CINSIYET değişkenine göre ODOKUMA1 puanlarına ilişkin özetleyici istatistikler:
midiPISA %>%
group_by(CINSIYET) %>%
summarise(n = n(),ortalama=mean(ODOKUMA1),sd=sd(ODOKUMA1),min=min(ODOKUMA1),max=max(ODOKUMA1)) ## # A tibble: 2 × 6
## CINSIYET n ortalama sd min max
## <dbl> <int> <dbl> <dbl> <dbl> <dbl>
## 1 1 3396 478. 83.7 236. 772.
## 2 2 3494 451. 89.6 176. 747.Elde edilen çıktıda, CINSIYET değişkenine göre gruplandırma yapılarak kız ve erkekler için frekans, ortalama, standart sapma, minimum ve maksimum değerler hesaplanmıştır.
Özetleyici istatistiksel bilgiler, veri setinde yer alan birden fazla kategorik değişken için de hesaplanabilir. Öğrencilerin cinsiyet ve sınıf düzeylerine göre elde edilen betimsel istatistikleri ortalamaya göre büyükten küçüğe sıralanmıştır. Yapılan bu işlem “betimsel” isimli nesneye atanmıştır.
betimsel <- midiPISA%>% # betimsel veri nesnesine atama
# CINSIYET ve SINIF değişkenlerine göre gruplara ayırma
group_by(CINSIYET,SINIF) %>%
# özetleyici bilgileri hesaplama
summarise(n = n(),ortalama=mean(ODOKUMA1),sd=sd(ODOKUMA1)) %>%
# gözlemleri ortalama değerleri büyükten küçüğe olacak şekilde sıralama
arrange(desc(ortalama))
head(betimsel)## # A tibble: 6 × 5
## # Groups: CINSIYET [2]
## CINSIYET SINIF n ortalama sd
## <dbl> <dbl> <int> <dbl> <dbl>
## 1 1 10 2707 482. 79.9
## 2 1 11 124 473. 85.0
## 3 1 9 548 462. 96.9
## 4 2 10 2653 459. 85.0
## 5 2 11 83 448. 87.9
## 6 2 9 747 422. 98.7Çıktıda olduğu gibi veri seti SINIF ve CINSIYET değişkenlerine göre gruplandırılarak ortalama değerler büyükten küçüğe sıralı olacak şekilde elde edilmiştir. Örneğin en yüksek ortalamaya sahip (482.2971) olan erkek ve 10. sınıftan 2707 öğrenci vardır. group_by() fonksiyonu ile elde ettiğiniz çıktılarda aşağıdaki gibi gruplandırılmış veri Groups çıktısı ile alınır.
Gruplandırılmış elde edilen veri setlerinde tekrar işlem yapmak istenirse ungroup() fonksiyonu kullanılabilir.
midiPISA %>%
#CINSIYET ve SINIF değişkenlerine göre gruplara ayırma
group_by(CINSIYET,SINIF) %>%
# özetleyici bilgileri hesaplama
summarise(n = n(),ortalama=mean(ODOKUMA1),sd=sd(ODOKUMA1)) %>%
# gözlemleri ortalama değerleri büyükten küçüğe olacak şekilde sıralama
arrange(desc(ortalama)) %>%
# grupları birleştirme
ungroup() ## # A tibble: 12 × 5
## CINSIYET SINIF n ortalama sd
## <dbl> <dbl> <int> <dbl> <dbl>
## 1 1 10 2707 482. 79.9
## 2 1 11 124 473. 85.0
## 3 1 9 548 462. 96.9
## 4 2 10 2653 459. 85.0
## 5 2 11 83 448. 87.9
## 6 2 9 747 422. 98.7
## 7 1 12 5 422. 96.6
## 8 2 8 8 363. 82.8
## 9 1 8 11 356. 62.5
## 10 1 7 1 344. NA
## 11 2 7 2 330. 62.1
## 12 2 12 1 322. NAGruplandırılmış veri setlerinde bazı fonksiyonlar çalışmayabileceği için, üretilen yeni veri seti başka amaçlarla kullanılacağında ungroup() fonksiyonu ile grupları birleştirmek gereklidir.
2.4 across()
Bir veri setinde aynı anda birden fazla sütuna aynı işlem uygulanmak istendiğinde dplyr paketi içindeki across() fonksiyonu sıklıkla kullanılmaktadır. Bu fonksiyon veri düzenleme ile ilgili birçok temel fonksiyon içinde düzgün çalışabilmektedir. Fakat genellikle select(), mutate(), filter() veya summarise() içinde kullanılır.
cols = argümanına sütunlar ve .fns = argümanına uygulanacak fonksiyonlar atanır.
midiPISA verisinde okuma puanı olası değer 1 ve 2 sütunlarına ait ortalama değerleri across() fonksiyonu ile hesaplayalım.
## # A tibble: 1 × 2
## ODOKUMA1_mean ODOKUMA2_mean
## <dbl> <dbl>
## 1 464. 464.ODOKUMA1 ve ODOKUMA2 sütunlarına ait ortalamalar hesaplanmış ve bu ortalama değerlerini veren sütunlar .names = “{col}_mean” ile isimlendirilmiştir.
Birden fazla istatistiksel bilgi hesaplanmak istendiğinde list() argümanı kullanılabilir. “OD” ile başlayan sütunlara ait ortalama ve standart sapma değerlerini hesaplayalım.
## # A tibble: 1 × 10
## ODOKUMA1_mean ODOKUMA1_sd ODOKUMA2_mean ODOKUMA2_sd ODOKUMA3_mean ODOKUMA3_sd
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 464. 87.8 464. 87.7 465. 87.1
## # ℹ 4 more variables: ODOKUMA4_mean <dbl>, ODOKUMA4_sd <dbl>,
## # ODOKUMA5_mean <dbl>, ODOKUMA5_sd <dbl>2.5 summarise() ve across()
dplyr paket fonksiyonlarının **_at,_if,_all** uzantılı varyasyonları bulunmaktadır. Bunlardan biri olan summarise_at() fonksiyonunu bir grup sütunun ortalamasını ve standart sapmasını hesaplamak gerektiğinde kullanabilirsiniz. summarise_at() fonksiyonu ile seçilecek değişkenler vars() fonksiyonu içinde belirtilebilir. Bu işlem select() işlemi yerine geçmektedir. Hesaplama işlemlerini ise list() fonksiyonu içinde tanımlayabilirsiniz.
## # A tibble: 1 × 4
## ODOKUMA1_mean ODOKUMA2_mean ODOKUMA1_sd ODOKUMA2_sd
## <dbl> <dbl> <dbl> <dbl>
## 1 464. 464. 87.8 87.7summarise_at() fonksiyonu kullanılmak istenildiğinde kullanımdan kaldırılmış olduğu (deprecated) uyarısı görünür. Bir fonksiyonun daha iyi bir alternatifi mevcut ise kullanımdan kaldırılabilir. Daha önce de bahsedilen across() fonksiyonu değişken seçmek için yukarıdaki örnekte vars() fonksiyonu yerine aşağıdaki şekilde kullanılabilir. Bu sayede summarise_at() fonksiyonu yerine summarise() fonksiyonu kullanılmış olur.
## # A tibble: 1 × 4
## ODOKUMA1_mean ODOKUMA1_sd ODOKUMA2_mean ODOKUMA2_sd
## <dbl> <dbl> <dbl> <dbl>
## 1 464. 87.8 464. 87.7summarise()fonksiyonlarındansummarise_all ()fonksiyonu ile tüm sütunlara istenilen fonksiyon uygulanabilir. Ancak bu fonksiyon kullanımdan kaldırıldığı için bu işleminsummarise()veacross()fonksiyonu ile nasıl yapıldığı gösterilmiştir.
## # A tibble: 1 × 32
## OGRENCIID_mean OGRENCIID_sd SINIF_mean SINIF_sd CINSIYET_mean CINSIYET_sd
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79203623. 2087. 9.84 0.458 1.51 0.500
## # ℹ 26 more variables: Anne_Egitim_mean <dbl>, Anne_Egitim_sd <dbl>,
## # Baba_Egitim_mean <dbl>, Baba_Egitim_sd <dbl>, OKUMA_ZEVK_mean <dbl>,
## # OKUMA_ZEVK_sd <dbl>, ST097Q01TA_mean <dbl>, ST097Q01TA_sd <dbl>,
## # ST097Q02TA_mean <dbl>, ST097Q02TA_sd <dbl>, ST097Q03TA_mean <dbl>,
## # ST097Q03TA_sd <dbl>, ST097Q04TA_mean <dbl>, ST097Q04TA_sd <dbl>,
## # ST097Q05TA_mean <dbl>, ST097Q05TA_sd <dbl>, ODOKUMA1_mean <dbl>,
## # ODOKUMA1_sd <dbl>, ODOKUMA2_mean <dbl>, ODOKUMA2_sd <dbl>, …Çıktıda tüm değişkenlerin eksik veriler silinerek ortalamasının alındığı görülmektedir.
Elinizdeki bir veri setinin sayısal (numeric) olan sütunlarının ortalamasını summarise_if() fonksiyonu ile hesaplayabilirsiniz. Bu hesaplamanın summarise() ve across() fonksiyonu ile nasıl yapıldığı gösterilmiştir.
## # A tibble: 1 × 32
## OGRENCIID_mean OGRENCIID_sd SINIF_mean SINIF_sd CINSIYET_mean CINSIYET_sd
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79203623. 2087. 9.84 0.458 1.51 0.500
## # ℹ 26 more variables: Anne_Egitim_mean <dbl>, Anne_Egitim_sd <dbl>,
## # Baba_Egitim_mean <dbl>, Baba_Egitim_sd <dbl>, OKUMA_ZEVK_mean <dbl>,
## # OKUMA_ZEVK_sd <dbl>, ST097Q01TA_mean <dbl>, ST097Q01TA_sd <dbl>,
## # ST097Q02TA_mean <dbl>, ST097Q02TA_sd <dbl>, ST097Q03TA_mean <dbl>,
## # ST097Q03TA_sd <dbl>, ST097Q04TA_mean <dbl>, ST097Q04TA_sd <dbl>,
## # ST097Q05TA_mean <dbl>, ST097Q05TA_sd <dbl>, ODOKUMA1_mean <dbl>,
## # ODOKUMA1_sd <dbl>, ODOKUMA2_mean <dbl>, ODOKUMA2_sd <dbl>, …Mevcut kodunuzu _if, _at veya _all işlevleri yerine across() işlevini kullanacak şekilde güncellemek istiyorsanız summarise_at(), summarise_all() ve summarise_if() fonksiyonlarının yerini summarise() fonksiyonu içinde de kullanılabilen across() yardımcı fonksiyonunu kullanabilirsiniz.
2.6 top_n()
top_n()fonksiyonu ile istediğiniz bir değişkenin en yüksek ya da en düşük değerlerine göre veri setinde seçim yapılabilir.
## x
## 1 10
## 2 6- Okuma puanı en yüksek olan beş kız ve beş erkek öğrencilerin bilgileri
midiPISA %>%
# CINSIYET ve okuma olası değer1 değişkenlerinin seçilmesi
select(CINSIYET,ODOKUMA1)%>%
# büyükten küçüğe okuma puanlarının sıralanması
arrange(desc(ODOKUMA1))%>%
# CINSIYET değişkenine göre verinin gruplandırılması
group_by(CINSIYET) %>%
# okuma puanına göre her kategoriye ait en yüksek 5'er öğrencinin görüntülenmesi
top_n(5,ODOKUMA1) ## # A tibble: 10 × 2
## # Groups: CINSIYET [2]
## CINSIYET ODOKUMA1
## <dbl> <dbl>
## 1 1 772.
## 2 1 748.
## 3 2 747.
## 4 1 743.
## 5 2 737.
## 6 1 719.
## 7 1 715.
## 8 2 714.
## 9 2 713.
## 10 2 707.2.7 top_n() & - operatörü
top_n() fonksiyonu, “-” ile birlikte kullanıldığında, veri setindeki en düşük ilgili özelliğe sahip öğrenci/lerin bilgilerini verir. Örneğin, okuma puanı en düşük olan beş kız ve beş erkek öğrencinin bilgilerini elde edelim:
midiPISA %>%
select(CINSIYET,ODOKUMA1)%>%
arrange(desc(ODOKUMA1))%>%
group_by(CINSIYET) %>%
# okuma puanına göre her kategoriye ait en düşük 5'er öğrencinin görüntülenmesi
top_n(-5,ODOKUMA1) ## # A tibble: 10 × 2
## # Groups: CINSIYET [2]
## CINSIYET ODOKUMA1
## <dbl> <dbl>
## 1 1 254.
## 2 1 253.
## 3 1 250.
## 4 1 242.
## 5 1 236.
## 6 2 220.
## 7 2 211.
## 8 2 199.
## 9 2 177.
## 10 2 176.Elde edilen çıktı incelendiğinde, okuma puanı en düşük 5 öğrenci hem erkek hem de kız öğrenciler olarak ayrı ayrı belirlenmiştir.
Bu bölümde veriyi bir üst düzeye toplama ile ilişki fonksiyonlara yer verilmiştir. Veri Düzenleme III bölümünde farklı veri setlerini birleştirme işlemlerine değinilecektir.
Bölüm 3 Veri Düzenleme III
3.1 join()
join() fonksiyonları iki veri setini istenilen şekilde birleştirme amacıyla kullanılır. Örneğin elimizde A ve B olmak üzere iki farklı veri seti olsun. Her iki veri setini birleştirmek istediğimizde bu veri setlerinden hangi satır veya sütunları seçeceğimizi, satırların eşleşip eşleşmeyeceğini hangi değişkenlerle belirleneceğinin bilinmesi gerekmektedir. Bu nedenle de her bir amaca yönelik join fonksiyon türleri belirlenmiştir. Bunlar; left_join(), right_join(), full_join(), inner_join(), semi_join(), anti_join() fonksiyonlarıdır.
3.2 left_join()
A %\>% left_join(B)ile A verisindeki tüm satırlar, mümkün olduğunda B verisi ile eşleştirilerek (olmadığında “NA” verir), hem A hem de B den gelen sütunlar alınır.

Şekil 1’de, left_join() fonksiyonu ile öncelikle X1 değişkenine ait tüm gözlemler alınmıştır. X2 değişkenine ait ID numarası “1” olan gözlem olmadığı için yeni veri setinde bu kısım kayıp veri (NA) olarak girilmiştir. Burada birleştirme yapılacak iki veri setine ait örnekteki gibi ortak bir değişkenin (“ID”) olması önemlidir.
Örnek bir veri seti üzerinden açıklayalım. midiPISA1, midiPISA verisinden OGRENCIID, CINSIYET ve ST097Q01TA, ST097Q02TA değişkenlerinin ve bu veri setinin ilk altı satırının seçilmesi ile oluşturulur.
midiPISA1 <- midiPISA %>% select(OGRENCIID,CINSIYET,ST097Q01TA,ST097Q02TA) #değişkenlerin seçimi
midiPISA1<-midiPISA1[1:6,] #veri setinin ilk 6 satırının seçilmesi
midiPISA1## # A tibble: 6 × 4
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2
## 2 79201064 2 3 2
## 3 79201118 1 2 3
## 4 79201275 2 2 2
## 5 79201481 2 3 3
## 6 79201556 2 3 3midiPISA1 verisinin oluşturulmasından sonra midiPISA2 verisi oluşturulur. Öncelikle midiPISA verisinden öğrenci id, okumaktan zevk alma ve okuma olası değer1 puanları değişkenleri seçilir. Ardından bu veri setinin ilk yedi satırı seçilir ve üçüncü satır silinir. Sonuç olarak altı satırlık bir midiPISA2 veri seti elde edilmiş olur.
#değişkenlerin seçimi
midiPISA2<- midiPISA %>% select(OGRENCIID,OKUMA_ZEVK,ODOKUMA1)
midiPISA2<-midiPISA2[1:7,] #veri setinin ilk 7 satırının seçilmesi
midiPISA2<-midiPISA2[-3,] #veri setinin 3. satırının çıkarılması
midiPISA2## # A tibble: 6 × 3
## OGRENCIID OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl>
## 1 79200768 -0.289 376.
## 2 79201064 0.604 512.
## 3 79201275 -1.15 393.
## 4 79201481 0.667 552.
## 5 79201556 0.357 441.
## 6 79201652 -0.0886 411.Elimizde bulunan midiPISA1 ve midiPISA2 veri setlerini kullanarak left_join() fonksiyonu ile birleştirme işlemi uygulanır.
## # A tibble: 6 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201118 1 2 3 NA NA
## 4 79201275 2 2 2 -1.15 393.
## 5 79201481 2 3 3 0.667 552.
## 6 79201556 2 3 3 0.357 441.Elde edilen çıktı incelendiğinde, midiPISA1 verisindeki tüm satırlar, midiPISA2 verisi ile eşleştirilmiş, “79201652”ıd numaralı öğrenci midiPISA1 de olmadığından hiç alınmamıştır. “79201118” ıd numaralı öğrenci ise midiPISA2 verisinde yer almadığında okumaktan zevk alma ve okuma olası değer1 değişkenleri “NA” olarak oluşturulmuştur.
3.3 right_join()
A %\>% left_join(B) ile B verisindeki tüm satırlar, mümkün olduğunda A verisi ile eşleştirilerek (olmadığında “NA” verir), hem A hem de B den gelen sütunlar alınır.
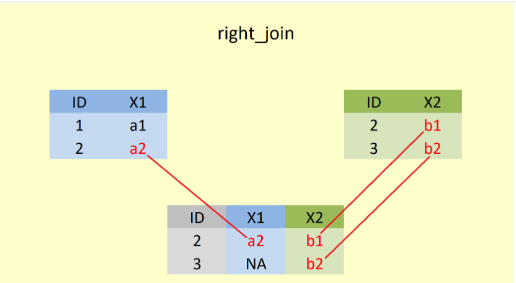
Şekil 2’de, right_join() fonksiyonu ile öncelikle X2 değişkenine ait tüm gözlemler alınmıştır. X1 değişkenine ait ID numarası “3” olan gözlem olmadığı için yeni veri setinde bu kısım kayıp veri(NA) olaraK girilmiştir. Burada da left_join() fonksiyonunda olduğu gibi birleştirme yapılacak iki veri setine ait ortak bir değişkenin (“ID”) olması önemlidir.
Örnek veri seti üzerinden açıklayalım:
## # A tibble: 6 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201275 2 2 2 -1.15 393.
## 4 79201481 2 3 3 0.667 552.
## 5 79201556 2 3 3 0.357 441.
## 6 79201652 NA NA NA -0.0886 411.Elde edilen çıktı incelendiğinde, midiPISA2 verisindeki tüm satırlar, midiPISA1 verisi ile eşleştirilmiş, “79201118”ıd numaralı öğrenci midiPISA2 de olmadığından oluşturulan veri setine hiç alınmamıştır.”79201652” ıd numaralı öğrenci ise midiPISA1 verisinde yer almadığında CINSIYET, ST097Q01TA,ST097Q01TA değişkenleri “NA” olarak oluşturulmuştur. Görüldüğü üzere left_join() ile right_join() fonksiyonları arasındaki fark eşleştirme öncesi temel alınacak ana veri setinin farklı olmasıdır. Fakat pratikte genellikle left_join() fonksiyonu kullanılır.
3.4 inner_join()
A %>% inner_join(B) ile sadece A ve B nin eşleşen satırlarını birleştirir. Yani hem A hem de B den gelen sütunları alır.

Şekil 3’te, inner_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak ortak olan satırlar yani 2. satır birleştirilir.
## # A tibble: 5 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201275 2 2 2 -1.15 393.
## 4 79201481 2 3 3 0.667 552.
## 5 79201556 2 3 3 0.357 441.“OGRENCIID” değişkeni ortak değişken olduğundan bu değişkene göre birleştirme işlemi yapılmış ve sadece her iki veri setinde yer alan öğrenciler seçilmiştir. Bu durumda “79201118” ve “79201652” id numaraya sahip öğrenciler birleştirme işleminden sonra yeni veri setinde yer almamıştır. Böylece yeni veri seti beş satırdan oluşmuştur.
3.5 full_join()
A %\>% full_join(B) ile A ve B veri setinde yer alan tüm satırları birleştirir. Hem A hem de B den gelen sütunları alır.
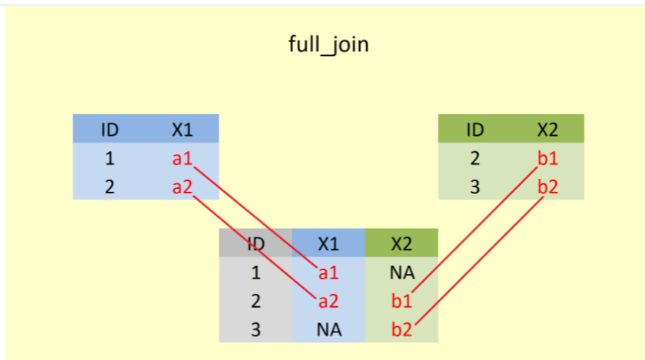
Şekil 4’te, full_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak iki veri setinde de yer alan tüm değişkenler birleştirilir.
## # A tibble: 7 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201118 1 2 3 NA NA
## 4 79201275 2 2 2 -1.15 393.
## 5 79201481 2 3 3 0.667 552.
## 6 79201556 2 3 3 0.357 441.
## 7 79201652 NA NA NA -0.0886 411.“OGRENCIID” değişkeni ortak değişken olduğundan bu değişkene göre birleştirme işlemi yapılmış ve her iki veri setinde yer alan tüm öğrenciler seçilmiştir. Bu durumda “79201118” ve “79201652” id numaraya sahip öğrenciler birleştirme işleminden sonra yeni veri setinde yer almıştır. Böylece yeni veri seti yedi satırdan oluşmuştur.
3.6 semi_join()
A %\>% semi_join(B) ile A veri setinin B ile eşleşen satırları alınarak sadece A dan gelen sütunlar yeni veri setinde yer alır.
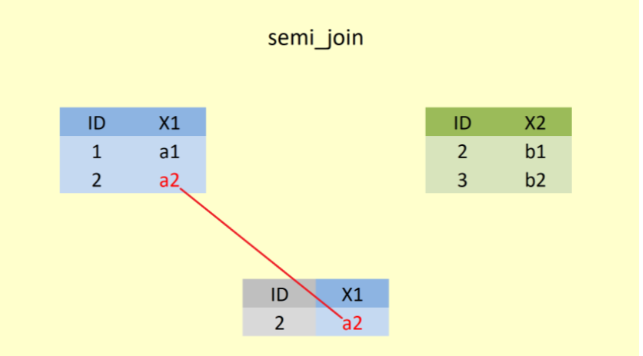
Şekil 5’te, semi_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak ortak olan satırlar yani 2. satır birleştirilir. Fakat yine sadece A veri setinde yer alan değişken ya da değişkenler alınır.
## # A tibble: 5 × 4
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2
## 2 79201064 2 3 2
## 3 79201275 2 2 2
## 4 79201481 2 3 3
## 5 79201556 2 3 3Çıktıda midiPISA1 verisinin midiPISA2 verisi ile eşleşen satırları ele alındığından “79201118” id numaralı öğrenci yeni veri setine dahil edilmemiştir. Ayrıca yeni veri setinde sadece midiPISA1 değişkeninde yer alan CINSIYET, ST097Q01TA, ST097Q02TA değişkenleri yer almıştır.
3.7 anti_join()
A %\>% anti_join(B) ile A’nın B ile eşleşemeyen satırları alınarak yeni veri setinde sadece A’dan gelen sütunlara yer verilir.
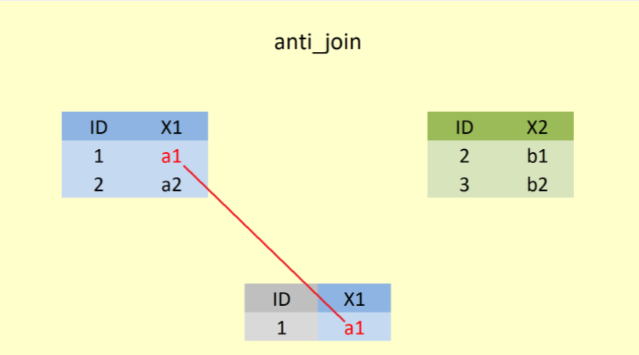
Şekil 6’da, anti_join() fonksiyonu ile öncelikle “ID” değişkeni baz alınarak ortak olmayan satırlar yani sadece 1. satır ve A veri setindeki değişken (X1) alınmıştır.
## # A tibble: 1 × 4
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA
## <dbl> <dbl> <dbl> <dbl>
## 1 79201118 1 2 3Çıktıda midiPISA1 verisinin midiPISA2 verisi ile eşleşmeyen satırları ele alındığından “79201118” id numaralı öğrenci yeni veri setine dahil edilmiştir. Ayrıca yeni veri setinde sadece midiPISA1 değişkeninde yer alan CINSIYET, ST097Q01TA, ST097Q02TA değişkenleri yer almıştır.
Not: Aynı değerleri içeren satırların olduğu sütunların eşleşmesi gerektiğini söyledik. Bunları birleştirme için aslında bir by = argümanı da kullanılır. Fakat birleştirme yapmak istediğimiz sütun/ların isimleri aynı olduğunda by = argümanını kullanmaya gerek kalmaz. Buraya kadar yapılan örnekler aşağıdaki gibi pipe operatörü kullanIlmadan da yapılabilir.
## # A tibble: 6 × 6
## OGRENCIID CINSIYET ST097Q01TA ST097Q02TA OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 2 1 2 -0.289 376.
## 2 79201064 2 3 2 0.604 512.
## 3 79201118 1 2 3 NA NA
## 4 79201275 2 2 2 -1.15 393.
## 5 79201481 2 3 3 0.667 552.
## 6 79201556 2 3 3 0.357 441.Elde edilen çıktı midiPISA1%>% left_join(midiPISA2) fonksiyonu ile elde edilen çıktı ile aynıdır. Fakat değişken isimleri farklı olduğunda by argümanını kullanmak anlamlı olabilir. Şimdi bununla ilgili bir örnek yapalım. Öncelikle midiPISA2 veri setindeki “OGRENCIID” değişken ismini “STDNTID” olarak değiştirelim.
## # A tibble: 6 × 3
## STDNTID OKUMA_ZEVK ODOKUMA1
## <dbl> <dbl> <dbl>
## 1 79200768 -0.289 376.
## 2 79201064 0.604 512.
## 3 79201275 -1.15 393.
## 4 79201481 0.667 552.
## 5 79201556 0.357 441.
## 6 79201652 -0.0886 411.midiPISA3 verisi aslında midiPISA2 verisinin aynısıdır sadece tek bir değişkenin ismi değişmiştir.
Veri setinde eşleştirme yapılması istenilen değişkenin farklı adları olduğunda aşağıdaki kod kullanılabilir.
## # A tibble: 6 × 5
## OGRENCIID OKUMA_ZEVK.x ODOKUMA1.x OKUMA_ZEVK.y ODOKUMA1.y
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 -0.289 376. -0.289 376.
## 2 79201064 0.604 512. 0.604 512.
## 3 79201275 -1.15 393. -1.15 393.
## 4 79201481 0.667 552. 0.667 552.
## 5 79201556 0.357 441. 0.357 441.
## 6 79201652 -0.0886 411. -0.0886 411.Bu bölümde farklı veri setlerini birleştirme işlemlerine yer verilmiştir. Veri Düzenleme IV bölümünde veri setlerini farklı formatlara getirme ve analize hazırlık işlemlerine değinilecektir.
Bölüm 4 Veri Düzenleme IV
Bir veriyi R ortamına aktardıktan sonra veri setinde yer alan tüm satır ya da sütunların doğru bir şekilde aktarılıp aktarılmadığı, değişken isimlerinin düzgün olup olmadığı yani özellikle sütun adlarında boşluk olmaması ya da farklı karakterler bulunmaması kontrol edilmelidir. İlk olarak R ortamına aktarılan boş satır ve sütunlar olup olmadığı filter() ve select() gibi fonksiyonlarla incelenebilir. Eksik verilerin nasıl temsil edildiği kontrol edilmelidir. NA,” “ (bosluk), ., 999 , 9999 vb. şekilde ifade edilen eksik veriler mutate() ve ifelse() ile düzenlenebilir. Ayrıca karakter (character) ve faktör (factor) değişkenlerinin de düzgün tanımlanıp tanımlanmadığı incelenmelidir.
Sütunlarda program, kadın ve erkek isimleri olan dağınık bir veri seti üzerinden veri düzenlemesinin temel aşamalarını gerçekleştirelim:
| Program | Kadın | Erkek |
|---|---|---|
| Olcme | 6 | 6 |
| Program | 5 | 5 |
| Yonetim | 7 | 8 |
| PDR | 5 | 3 |
Bir veri setindeki gözlem, değişken isim ve değişken değerlerinin ne olduğu öncelikle belirlenmelidir. Örnekteki veri setinde her bir programda yer alan öğrencilerin cinsiyete göre dağılımı gözlem; program, CINSIYET, frekans ise değişkenleri oluşturmalıdır. Program: Olcme, Program, Yonetim, PDR; CINSIYET: Kadın, Erkek kategorilerinden oluşmalıdır. Bunların değişken değeri olması gerekiyor, örnekteki gibi sütun başlığı değil. Frekansların ise iki sütuna dağıldığı görülmektedir.
Örnekte verilen dağınık verinin olması gereken düzgün veri hali aşağıda yer almaktadır.
| Program | CINSIYET | Frekans |
|---|---|---|
| Olcme | Kadın | 6 |
| Olcme | Erkek | 6 |
| Program | Kadın | 5 |
| Program | Erkek | 5 |
| Yonetim | Kadın | 7 |
| Yonetim | Erkek | 8 |
| PDR | Kadın | 5 |
| PDR | Erkek | 3 |
Düzgün veri seti incelendiğinde, değişkenlerin sütunlarda, gözlemlerin satırlarda olduğu görülmektedir. Bu veri setinde program, CINSIYET ve Frekans olmak üzere üç farklı değişken bulunmaktadır. Değişken adları mümkün olduğunca örnekte olduğu gibi anlamlı olmalıdır.
Aslında çok sayıda satırı anlamlandırmak, çok sayıda sütunu anlamlandırmaktan daha kolaydır. Verinin bu şekilde düzenlenmesi dplyr, ggplot2, plotly, lattice gibi paketleri rahat kullanabilmek için oldukça önemlidir. Hiyerarşik ve karma modeller için de verinin düzgün olması gerekmektedir. Ayrıca düzgün bir veri seti, eksik değerler ve dengesiz tekrarlanan ölçüm verileriyle ilgili daha az sorun sağlar.
4.1 gather()
gather() fonksiyonu bir dizi sütun alır ve onları iki yeni sütuna (kendi adını verebileceğin) dönüştürür.
Fonksiyonun kullanım şekli;
- A key: Orijinal sütun adlarını saklayan bir anahtar.
- A value: Bu orijinal sütunlardaki değerlere sahip bir değer.
Fonksiyonun kullanımını göstermek için örnek bir veri seti üzerinde çalışalım.
genisveri<- midiPISA %>% select(OGRENCIID,ODOKUMA1:ODOKUMA5) #belli değişkenlerin seçilmesi
genisveri %>% head(6) # verinin ilk 6 satırının görüntülenmesi## # A tibble: 6 × 6
## OGRENCIID ODOKUMA1 ODOKUMA2 ODOKUMA3 ODOKUMA4 ODOKUMA5
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 376. 418. 421. 414. 434.
## 2 79201064 512. 473. 564. 485. 500.
## 3 79201118 396. 414. 423. 452. 392.
## 4 79201275 393. 429. 365. 383. 379.
## 5 79201481 552. 570. 563. 531. 532.
## 6 79201556 441. 416. 407. 437. 473.Elde edilen çıktıda öğrenci ıd ve beş okuma olası değerinin yer aldığı toplam altı değişkenden oluşan veri seti görüntülenmektedir. Bu değişkenler sütunlarda yer almaktadır. gather() fonksiyonu geniş veriyi, uzun veri haline getirir.
uzun <- genisveri %>% gather(O_OD,okumapuan,ODOKUMA1:ODOKUMA5)
uzun %>% arrange(OGRENCIID) %>% head(10)## # A tibble: 10 × 3
## OGRENCIID O_OD okumapuan
## <dbl> <chr> <dbl>
## 1 79200001 ODOKUMA1 450.
## 2 79200001 ODOKUMA2 458.
## 3 79200001 ODOKUMA3 413.
## 4 79200001 ODOKUMA4 430.
## 5 79200001 ODOKUMA5 439.
## 6 79200002 ODOKUMA1 669.
## 7 79200002 ODOKUMA2 666.
## 8 79200002 ODOKUMA3 685.
## 9 79200002 ODOKUMA4 665.
## 10 79200002 ODOKUMA5 660.Çıktı incelendiğinde, oluşan veride ODOKUMA1, ODOKUMA2, ODOKUMA3, ODOKUMA4 ve ODOKUMA5 okumapuanı değişkeninin değerleri hâline gelmiştir. Çıktıda görüldüğü gibi, şimdi ID dışında iki sütunumuz var: Biri kategorik diğeri sayısal değerleri içerir. Her katılımcı icin beş farklı okuma olası değeri olduğu için her bir ID değeri beş kere tekrarlanmaktadır. Burada veri setinin ilk on satırı görüntülendiğinden sadece 79200001 ve 79200002 id numaralı öğrenciler görüntülenmektedir.
4.2 spread()
spread()fonksiyonu uzun veriden tekrar geniş veri olusturmaya yarar.gather()fonksiyonunun tersi olan işlevi yapar
tekrar_genis <- uzun %>% spread(O_OD,okumapuan) # geniş veri oluşturulması
tekrar_genis %>% head(6) # ilk altı satırın görüntülenmesi## # A tibble: 6 × 6
## OGRENCIID ODOKUMA1 ODOKUMA2 ODOKUMA3 ODOKUMA4 ODOKUMA5
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200001 450. 458. 413. 430. 439.
## 2 79200002 669. 666. 685. 665. 660.
## 3 79200003 452. 502. 444. 456. 437.
## 4 79200004 347. 317. 339. 325. 367.
## 5 79200005 467. 498. 415. 471. 446.
## 6 79200006 366. 364. 384. 420. 351.Öğrenci id değişkeni ile birlikte okuma puanlarının isimlerinin ve değerlerinin yer aldığı iki sütundan oluşan (id hariç) uzun veri seti, beş olası değerinin de ayrı birer sütun olarak yer aldığı toplam beş sütundan(id hariç) oluşan geniş veri setine dönüştürülmüştür.
4.3 pivot_longer() ve pivot_wider()
Verilerin girilme şekli genellikle geniş ve uzun olmak üzere iki formattan oluşur. Geniş formatta veriler, bir gözlemin özellikleri veya yanıtlar tek bir satırda verilir. Genellikle veriler bu şekilde girilmesine rağmen geniş format her zaman kullanışlı olmayabilir. Geniş verinin uzun veriye dönüştürülmesini gather() ve uzun verinin geniş veriye dönüşütürülmesini spread()fonksiyonu ile gerçekleştirdik. Ancak bahsedilen iki fonksiyona alternatif yeni fonksiyonlar üretilmiştir. Bu bölümde bu iki fonksiyon açıklanacaktır.
midiPISA verisetinden daha az değişken içerecek şekilde bir geniş veri seti örneği oluşturalım.
genisveri <- midiPISA %>% select(OGRENCIID,ODOKUMA1:ODOKUMA5) #belli değişkenlerin seçilmesi
genisveri %>% head(6) # verinin ilk 6 satırının görüntülenmesi## # A tibble: 6 × 6
## OGRENCIID ODOKUMA1 ODOKUMA2 ODOKUMA3 ODOKUMA4 ODOKUMA5
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 376. 418. 421. 414. 434.
## 2 79201064 512. 473. 564. 485. 500.
## 3 79201118 396. 414. 423. 452. 392.
## 4 79201275 393. 429. 365. 383. 379.
## 5 79201481 552. 570. 563. 531. 532.
## 6 79201556 441. 416. 407. 437. 473.Elde edilen çıktıda öğrenci ıd ve beş okuma olası değerinin yer aldığı toplam altı değişkenden yer alan veri seti görüntülenmektedir. Bu değişkenler sütunlarda yer almakta olup geniş veri formatındadır. pivot_longer fonksiyonu geniş veriyi, uzun veri haline getirir.
uzun <- genisveri %>% pivot_longer(names_to="okumapuan",values_to="deger",cols=ODOKUMA1:ODOKUMA5)
uzun %>% head(5)## # A tibble: 5 × 3
## OGRENCIID okumapuan deger
## <dbl> <chr> <dbl>
## 1 79200768 ODOKUMA1 376.
## 2 79200768 ODOKUMA2 418.
## 3 79200768 ODOKUMA3 421.
## 4 79200768 ODOKUMA4 414.
## 5 79200768 ODOKUMA5 434.Çıktı incelendiğinde, oluşan veride ODOKUMA1, ODOKUMA2, ODOKUMA3, ODOKUMA4 ve ODOKUMA5 ayrı bir sütunun değerleri haline gelmiştir. Bu okuma puan türlerinin sütununun yer aldığı değişken names_to argümanı ile “okumapuan” olarak isimlendirilmiştir. Ayrıca values_to argümanı ise okuma puanı değerlerinin yer aldığı sütun isimlendirilmiştir. Çıktıda görüldüğü gibi, şimdi ID dışında iki sütunumuz var: Biri okuma puanı türü için, diğeri okuma puanı türleri için. Her katılımcı icin beş farklı okuma olası değeri olduğu için her bir ID değeri beş kere tekrarlanmaktadır. Burada veri setinin ilk beş satırı görüntülendiğinden sadece 792200768 id numaralı öğrencinin değerleri görüntülenmektedir.
Bir veri setini daha iyi yorumlayabilmek amacıyla uzun veri formatından geniş veri formatına dönüştürülür. Genellikle bir gözlem için değerlerin birden çok satırda yer aldığı durumlarda tercih edilir. Bunun için pivot_wider() fonksiyonu kullanılır.
## # A tibble: 5 × 6
## OGRENCIID ODOKUMA1 ODOKUMA2 ODOKUMA3 ODOKUMA4 ODOKUMA5
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 79200768 376. 418. 421. 414. 434.
## 2 79201064 512. 473. 564. 485. 500.
## 3 79201118 396. 414. 423. 452. 392.
## 4 79201275 393. 429. 365. 383. 379.
## 5 79201481 552. 570. 563. 531. 532.4.4 separate()
separate() fonksiyonu bir sütunu birden çok sütuna ayırır. Değerlerin sütun adlarına gömüldüğü toplanmış verilerde ortaktır. Oluşan veride okuma puanı değerlerinin karakter ve sayısal değerlerini ayırmak için separate()fonkisyonu kullanılabilir.
uzun_v1 <- uzun %>% separate(okumapuan, c("OD","Sayi"),"MA") # bir sütunu iki sütuna ayırma
uzun_v1 %>% head(3) #ilk üç satırın görüntülenmesi## # A tibble: 3 × 4
## OGRENCIID OD Sayi deger
## <dbl> <chr> <chr> <dbl>
## 1 79200768 ODOKU 1 376.
## 2 79200768 ODOKU 2 418.
## 3 79200768 ODOKU 3 421.Elde edilen çıktıya göre, okuma puanı olası değerlerinin yer aldığı sütun ikiye ayrılarak OD sütunu ve sayı sütunundan oluşmaktadır. Çıktının ilk üç satırı görüntülendiği için tek bir öğrenciye ait üç olası değerler yer almaktadır.
4.5 unite()
separate() fonksiyonunun tam tersi olarak iki sütunu alıp tek sütunda birleştirir.
uzun_birles <- uzun_v1 %>% unite(ODOKUMA, OD, Sayi, sep = "_") # sütun birleştirmenin yapılması
uzun_birles %>% head(3) # ilk üç satırın görüntülenmesi## # A tibble: 3 × 3
## OGRENCIID ODOKUMA deger
## <dbl> <chr> <dbl>
## 1 79200768 ODOKU_1 376.
## 2 79200768 ODOKU_2 418.
## 3 79200768 ODOKU_3 421.Elde edilen çıktı incelendiğinde, öğrenci id değişkeni hariç iki sütunun olduğu görülmektedir. ODOKUMA sütunu, okuma puanlarının isimlerinden, değer ise okuma olası puanı değerlerinden oluşmaktadır.
separate() fonksiyonunun alternatifi extract() ve unite() fonksiyonları ile yapılabilecek olan işlemler mutate() fonksiyonu ile de yapılabilir.
Bu alternatiflerin uygunluğunun özel kullanım durumunuza ve verilerinizin niteliğine bağlı olduğunu unutmayın. Paketler zaman içinde yeni fonksiyonlara veya iyileştirmelere sahip olabileceğinden, en son güncellemeler için her zaman fonksiyon yardım sayfalarını kontrol etmenizi öneriyoruz.
Bölüm 5 Betimleyici İstatistikler
Bu bölümde veri setine ait en sık kullanılan betimleyici istatistikler hesaplanmıştır.
5.1 Minimum ve maksimum değerler
min() ve max() fonksiyonları sayesinde veri setinin minimum ve maksimum değerleri bulunabilir:
## [1] 175.608midiPISA verisinin minimum değeri 175.61 olarak bulunmuştur.
## [1] 771.508midiPISA verisinin maksimum değeri 771.51 olarak bulunmuştur.
Alternatif olarak range() fonksiyonu: size doğrudan minimum ve maksimum değerleri verir. range() fonksiyonunun çıktısının aslında minimum ve maksimum değerleri (bu sırayla) içeren bir nesne olduğuna dikkat edin. Bu, aslında minimuma şu şekilde erişebileceğiniz anlamına gelir:
## [1] 175.608## [1] 771.508Elde edilen çıktıda, sırasıyla midiPISA verisindeki okuma olası değeri1’ e ait minimum ve maksimum değerleri sırasıyla görüntülenmiştir.
5.2 Ortalama
Ortalama, mean() fonksiyonu ile hesaplanabilir:
## [1] 464.2299midiPISA verisinin ortalama değeri 464.23 olarak bulunmuştur.
Veri setinde en az bir eksik(kayıp) değer varsa, ortalama NA hariç tutularak hesaplanabilir. Bunun için na.rm_TRUE argümanı kullanılabilir. Bu argüman sadece ortalama için değil, R’da sunulan çoğu fonksiyon için kullanılabilir.
## [1] 464.2299midiPISA verisine ait okuma olası değeri1 de kayıp değer olmadığı için ortalama değer yine 464.23 olarak bulunmuştur. Ayrıca kırpılmış bir ortalama için mean(midiPISA$O_OD1, trim = 0.10) kullanılabilir ve trim bağımsız değişkenini ihtiyaçlarınıza göre değiştirebilirsiniz.
5.3 Medyan
Medyan(ortanca değer), median() fonksiyonu sayesinde hesaplanabilir:
## [1] 463.403midiPISA verisinin medyanı 463.405 olarak bulunmuştur.Aynı zamandabu değer -quantile() fonksiyonu ile de hesaplanabilir.
## 50%
## 463.4035.4 I. ve III. Çeyrekler
Medyan gibi, birinci ve üçüncü çeyrekler de quantile() işlevi sayesinde ve ikinci bağımsız değişkenin 0.25 veya 0.75 olarak ayarlanmasıyla hesaplanabilir:
## 25%
## 402.5635midiPISA verisinin I.çeyrekler 402.5625 olarak bulunmuştur.
## 75%
## 525.7188midiPISA verisinin III.çeyrekler 525.72 olarak bulunmuştur.
5.5 Standart sapma ve varyans
Standart sapma ve varyans, sd() ve var() fonksiyonları ile hesaplanır:
## [1] 87.78006midiPISA verisinin standart sapması 87.78 olarak bulunmuştur.
## [1] 7705.339midiPISA verisinin varyansı 7705.345 olarak bulunmuştur.
Standart sapma ve varyansın bir örneklem veya popülasyon için hesaplanmasının farklı olduğu hatırlanmalıdır (örneklem ve popülasyon arasındaki fark ilgili kaynaklardan incelenmelidir). R’de standart sapma ve varyans, veriler bir örneklem temsil ediyormuş gibi hesaplanır. Birden fazla değişkenin standart sapmasını veya varyansını aynı anda hesaplamak için, ikinci bağımsız değişken olarak uygun istatistiklerle birlikte lapply() fonksiyonu ile kullanılmalıdır.
midiPISA %>%
# "O_" başlayan ve "OD" içeren değişkenlerin seçimi
select(starts_with("OD") & contains("MA")) %>%
lapply(.,sd) # her bir değişkenin standart sapmasının hesaplanması## $ODOKUMA1
## [1] 87.78006
##
## $ODOKUMA2
## [1] 87.696
##
## $ODOKUMA3
## [1] 87.07692
##
## $ODOKUMA4
## [1] 87.40305
##
## $ODOKUMA5
## [1] 87.21323Çıktıda da görüldüğü üzere, veri setinde “O” ile başlayan ve “OD” içeren beş değişkene ait standart sapma değerleri hesaplanır.
Aynı işlemi veri seti olarak elde etmek istiyorsanız summarise() fonksiyonunu kullabailirsiniz.
midiPISA %>%
# "O_" başlayan ve "OD" içeren değişkenlerin seçimi
select(starts_with("OD") & contains("MA")) %>%
summarise(across(everything(), list(sd = sd),na.rm=TRUE)) # her bir değişkenin standart sapmasının hesaplanması## # A tibble: 1 × 5
## ODOKUMA1_sd ODOKUMA2_sd ODOKUMA3_sd ODOKUMA4_sd ODOKUMA5_sd
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 87.8 87.7 87.1 87.4 87.25.6 Tüm özet istatistikler
summary() fonksiyonu ise betimleyici istatistikleri özet olarak verir.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 175.6 402.6 463.4 464.2 525.7 771.5Bu tanımlayıcı istatistikleri gruba göre hesaplamak istenirse by() fonksiyonu kullanıılır.
## midiPISA$CINSIYET: 1
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 236.4 418.2 477.6 478.1 536.9 771.5
## ------------------------------------------------------------
## midiPISA$CINSIYET: 2
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 175.6 387.5 448.0 450.7 512.2 747.5lapply() kullanımında bağımsız değişkenler veri setinin adı, gruplama değişkeni ve özet fonksiyonudur. Bu sıra takip edilmeli veya bu sıra takip edilemiyorsa argümanların adı belirtilmelidir.
Daha açıklayıcı istatistiklere ihtiyaç varsa, psych paketindeki describe() fonksiyonu kullanılmalıdır.
library(psych)
describe(midiPISA %>%
select(CINSIYET,ODOKUMA1)) # özetleyici istatistiklerinin hesaplanması## vars n mean sd median trimmed mad min max range skew
## CINSIYET 1 6890 1.51 0.50 2.0 1.51 0.00 1.00 2.00 1.0 -0.03
## ODOKUMA1 2 6890 464.23 87.78 463.4 463.90 91.11 175.61 771.51 595.9 0.04
## kurtosis se
## CINSIYET -2.0 0.01
## ODOKUMA1 -0.3 1.065.7 Değişkenlik katsayısı
Değişkenlik katsayısı stat.desc() ile veya manuel olarak hesaplanarak bulunabilir (Değişkenlik katsayısının standart sapmanın ortalamaya bölümü olduğu hatırlanmalıdır):
library(pastecs) # paketin aktifleştirilmesi
round(stat.desc(midiPISA %>%
select(CINSIYET,OKUMA_ZEVK)),2) # değişkenlik katsayısının hesaplanması## CINSIYET OKUMA_ZEVK
## nbr.val 6890.00 6821.00
## nbr.null 0.00 0.00
## nbr.na 0.00 69.00
## min 1.00 -2.73
## max 2.00 2.66
## range 1.00 5.39
## sum 10384.00 4659.70
## median 2.00 0.64
## mean 1.51 0.68
## SE.mean 0.01 0.01
## CI.mean.0.95 0.01 0.02
## var 0.25 0.95
## std.dev 0.50 0.98
## coef.var 0.33 1.43Seçilen CINSIYET ve OKUMA_ZEVK değişkenlerinin değişkenlik katsayıları hesaplanmış ve sonuçlar round ile virgülden sonra iki basamak olacak şekilde yuvarlanmıştır.
5.8 Mod
Bir değişkenin modunu bulmak için table() ve sort() fonksiyonları kullanarak hesaplanmalıdır.
##
## 0 1 2 3 4 5 6
## 695 1882 1362 575 675 759 887##
## 1 2 6 5 0 4 3
## 1882 1362 887 759 695 675 575table() fonksiyonu, her bir benzersiz değer için oluşum sayısını verir, ardından sort() decreasing = TRUE argümanı ile oluşum sayısını en yüksekten en düşüğe doğru görüntüler.
5.9 Frekans tablosu oluşturma
Herhangi bir ek işlem (yani veri işleme) yapmadan içe aktarılan veri setini kullanarak örneklemin demografik özellikleri hakkında bazı temel tanımlayıcı bilgiler hesaplanabilir.
Veri kümesi midiPISA kullanılarak Anne_Egitim (anne eğitim düzeyi) değişkenine göre gruplama yapılır. Ardından her gruptaki gözlemlerin sayısı bulunur ve gruplandırma kaldırılır.
midiPISA %>%
group_by(Anne_Egitim) %>% # Anne_Egitim e göre gruplandırma
count() %>% # frekans tablosu oluşturma
ungroup() # gruplandırmanın kaldırılması## # A tibble: 8 × 2
## Anne_Egitim n
## <dbl> <int>
## 1 0 695
## 2 1 1882
## 3 2 1362
## 4 3 575
## 5 4 675
## 6 5 759
## 7 6 887
## 8 NA 55group_by() fonkisyonu veri setinin yüzey düzeyinde değişikliklere neden olmaz, bunun yerine temel yapıyı değiştirir, böylece gruplar belirtilirse, daha sonra çağrılan fonksiyonlar gruplama değişkeninin her düzeyinde ayrı ayrı gerçekleştirilir. Bu gruplama oluşturulan nesnede kalır, bu nedenle nesne üzerinde gelecekte yapılacak işlemlerin gruplar tarafından bilinmeden gerçekleştirilmesini önlemek için ungroup() ile kaldırılması önemlidir.
Bu nedenle yukarıdaki kod, Anne_Egitim değişkeninin yani anne eğitim düzeyinin her bir grubundaki gözlem sayısını sayar. Eğer sadece toplam gözlem sayısına ihtiyacınız varsa, group_by() ve ungroup() satırlarını kaldırabilirsiniz, böylece işlemi gruplar yerine tüm veri seti üzerinde gerçekleştirebilirsiniz:
Benzer şekilde, örneklemin ortalama başarısı (ve SD’sini) hesaplanmak istendiğinde dplyr/tidyverse paketindeki summarise() fonkisyonu kullanılabilir.
midiPISA %>%
summarise(ort = mean(ODOKUMA1), # ortalama
sd = sd(ODOKUMA1), # standart sapma
n = n()) # frekans hesaplama## # A tibble: 1 × 3
## ort sd n
## <dbl> <dbl> <int>
## 1 464. 87.8 6890Bu kod, başarı ortalamasının hesaplanmasının sonucunu içeren ort adlı bir sütun biçiminde özet veriler üretir. Daha sonra aynı işlemi standart sapma için yapan sd sütununu oluşturur. Son olarak, istatistiği hesaplamak için kullanılan değerlerin sayısını n adlı bir sütuna eklemek için n() fonksiyonu kullanır.
Yukarıdaki kodun bu işlemin sonucunu kaydetmeyeceğini, sadece konsolda çıktısını vereceğini unutmayın. İleride kullanmak üzere kaydetmek isterseniz, “<-” notasyonunu kullanarak bir nesnede saklanabilir ve daha sonra nesne adını yazarak yazdırılabilir. Son olarak, group_by() fonksiyonu özet istatistikleri hesaplarken aynı şekilde çalışacaktır. group_by() fonksiyonundan sonra çağrılan işlevin çıktısı gruplama değişkeninin her düzeyi için üretilecektir.