Bölüm 4 Veri Yapıları
R’da pek çok veri yapısı mevcuttur. Bu kitapta özellikle vektörler, faktörler, matrisler, diziler, listeler ve data frame’lere yer verilmiştir.
4.1 Vektörler (vectors)
Vektör, aynı tür verilerin bir araya gelmesiyle oluşan tek boyutlu bir veri yapısıdır. Vektörler sayısal, karakter ya da mantıksal verilerden oluşabilir. R’da vektörleri oluşturmak için c() fonksiyonu kullanılabilir.
# üç farklı veri türünde vektör nesnelerin oluşturulması
sayisal <- c(5, 10, 15)
karakter <- c("x", "y", "z")
mantiksal <- c(TRUE, FALSE, TRUE)
# farklı tür veriler birleştirilirse ne olur
ornek1 <- c(30, "k", 5, "c")
ornek1## [1] "30" "k" "5" "c"## [1] "character"## [1] "numeric"## [1] "character"Farklı tür veriler birleştirildiğinde genellikle karakter vektörleri elde edilir (ornek3 nesnesi gibi). Buna karşın TRUE, FALSE birer eleman olarak vektöre eklenirse, bunlar sırası ile 1 ve 0 olarak davranır. Bu nedenle ornek2 nesnesi nümerik bir vektördür. Yukarıda verilen sayisal, karakter ve mantiksal nesneleri de birer vektördür. Vektörlerin uzunlukları length() fonksiyonu ile bulunabilir. Vektör türlerine ise typeof() fonksiyonu ile bakılabilir.
# iki ayrı vektörün oluşturulması
sinif <- c("Yagiz", "Deniz", "Doruk", "Cagan", "Utku", "Sarp")
notlar <- c(90, 95, 100, 80, 90, 95)
# vektörün uzunluğunu bulmak için
length(sinif)## [1] 6## [1] 6## [1] "character"## [1] "double"4.2 Faktörler (factors)
Faktörler kategorik/kesikli/süreksiz veriler için kullanılır. Faktör nesnelerinin aldığı değerlere düzey (level) denir. Karakter veri türü çoğunlukla grafiklerin adlandırılması, satır veya sütun adlarının verilmesi gibi amaçlar ile kullanılırken, faktörler veri setindeki süreksiz değişkenleri (variables) gösterir. Faktörler analizlerde grupları gösterir. Faktörler karakter veri türünde ya da sayısal veri türünde olabilir.
# bir karakter vektörü oluşturma ve bunu faktöre dönüştürme
cinsiyetler <- c("erkek", "erkek", "erkek", "kadin", "erkek", "kadin", "kadin")
cinsiyetler <- factor(cinsiyetler)
cinsiyetler## [1] erkek erkek erkek kadin erkek kadin kadin
## Levels: erkek kadinFaktörler düzeylerine göre sıralanabilir. Bunun için ordered() fonksiyonu kullanılabilir.
# bir karakter vektörü oluşturma ve bunu düzeyleri olan bir faktöre dönüştürme
beden <- c("M", "M", "S", "S", "L")
beden <- ordered(beden, levels = c("S", "M", "L"))
beden## [1] M M S S L
## Levels: S < M < LYukarıdaki örnekte bedenler sırasıyla ‘small’, ‘medium’ ve ‘large’ olarak sıralanmıştır.
4.3 Matrisler (matrices)
Matrisler, vektörler gibi tek bir tür veri içerir. Buna karşın, vektörler tek boyutlu iken matrisler iki boyutlu veri yapılarıdır. Matris oluşturmanın birden fazla yolu vardır. Eşit uzunluktaki vektörler birleştirilerek matris oluşturulabilir. Sütunların birleştirilmesi için cbind(), satırların birleştirilmesi için rbind() fonksiyonları kullanılır.
# öğrencilerin boyları için bir vektör, kiloları için başka bir vektör oluşturma
ogrenci_boy <- c(162, 168, 175, 182, 140)
ogrenci_kilo <- c(48, 50, 52, 55, 48)
mm_1 <- cbind(ogrenci_boy, ogrenci_kilo)
mm_1## ogrenci_boy ogrenci_kilo
## [1,] 162 48
## [2,] 168 50
## [3,] 175 52
## [4,] 182 55
## [5,] 140 48## [,1] [,2] [,3] [,4] [,5]
## ogrenci_boy 162 168 175 182 140
## ogrenci_kilo 48 50 52 55 48## [1] "matrix" "array"## [1] "matrix" "array"byrow argümanına dikkat ederek matris oluşturulabilir.
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 2 3 4 5
## [2,] 6 7 8 9 10
## [3,] 11 12 13 14 15
## [4,] 16 17 18 19 20## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20Yukarıdaki örnekten de anlaşılacağı üzere byrow argümanının olağan değeri FALSE (ya da kısaca F) şeklindedir. Bu argüman yazılmadan matrix() fonksiyonu kullanıldığında, argüman sanki FALSE olarak girilmiş gibi matris oluşturulacaktır. Bu argüman ile 1’den 20’ye kadar olan tam sayıların satırlar bazında mı sütunlar bazında mı sıralacağı R’a söylenmiş olur.
4.4 Diziler (arrays)
Diziler, vektörlerin ve matrislerin genelleştirilmiş halidir. Vektörler tek, matrisler ise iki boyutlu dizilerdir. Diziler, tek tür veri içerebilir. Dizi oluşturmak için array() fonksiyonundan yararlanılır.
## [1] NA## , , 1
##
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 7 9 11
## [2,] 8 10 12
##
## , , 3
##
## [,1] [,2] [,3]
## [1,] 13 15 17
## [2,] 14 16 18
##
## , , 4
##
## [,1] [,2] [,3]
## [1,] 19 21 23
## [2,] 20 22 24vektor_a <- c(5, 9, 3)
vektor_b <- c(10, 11, 12, 13, 14, 15)
sonuc <- array(c(vektor_a, vektor_b), dim = c(3, 3, 2))
sonuc## , , 1
##
## [,1] [,2] [,3]
## [1,] 5 10 13
## [2,] 9 11 14
## [3,] 3 12 15
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 5 10 13
## [2,] 9 11 14
## [3,] 3 12 154.5 Listeler (lists)
Listeler vektörlere benzer ancak vektörlerden farklı olarak herhangi bir veri türünde veri içerebilir. Esnek bir veri yapısıdır. Listelerde hem farklı türden, hem de farklı uzunlukta veriler yer alabilir. Listeler list() fonksiyonu ile oluşturulabilir.
# bir listeye koymak için üç ayrı vektör oluşturma
ad <- c("Ad1", "Ad2", "Ad3", "Ad4", "Ad5", "Ad6")
boy <- c(180, 181, 188, 170, 172, 175, 181)
kilo <- c(80, 85, 55)
# üç vektörden oluşan bir liste oluşturma
liste <- list(ad, boy, kilo)
liste## [[1]]
## [1] "Ad1" "Ad2" "Ad3" "Ad4" "Ad5" "Ad6"
##
## [[2]]
## [1] 180 181 188 170 172 175 181
##
## [[3]]
## [1] 80 85 55## List of 3
## $ : chr [1:6] "Ad1" "Ad2" "Ad3" "Ad4" ...
## $ : num [1:7] 180 181 188 170 172 175 181
## $ : num [1:3] 80 85 55# liste isimli listeye iki vektör daha ekleme
liste2 <- list(liste, ilk3sayi = c(1, 2, 3), mantik = c(T, F, F, F, T))
liste2## [[1]]
## [[1]][[1]]
## [1] "Ad1" "Ad2" "Ad3" "Ad4" "Ad5" "Ad6"
##
## [[1]][[2]]
## [1] 180 181 188 170 172 175 181
##
## [[1]][[3]]
## [1] 80 85 55
##
##
## $ilk3sayi
## [1] 1 2 3
##
## $mantik
## [1] TRUE FALSE FALSE FALSE TRUE## List of 3
## $ :List of 3
## ..$ : chr [1:6] "Ad1" "Ad2" "Ad3" "Ad4" ...
## ..$ : num [1:7] 180 181 188 170 172 175 181
## ..$ : num [1:3] 80 85 55
## $ ilk3sayi: num [1:3] 1 2 3
## $ mantik : logi [1:5] TRUE FALSE FALSE FALSE TRUE4.6 Data Frame’ler
R’da data frame’ler data.frame() fonksiyonu ile oluşturulabilir. R’a farklı programlardan aktarılan veriler genelde data frame olarak kaydedilir. Bu data frame’ler matrislere çok benzer, ancak data frame’lerde farklı sütunlarda yer alan veriler farklı türlerde olabilir. Matrislerde tüm veriler aynı tür olmak zorundadır. Data frame kavramı farklı kaynaklarda veri seti ya da veri çerçevesi olarak çevrilmiştir. Ancak bu kitapta orijinal haliyle kullanılmıştır. Bu şekli ile kullanımına yazılım ile ilgili yabancı dildeki kaynaklarda sıklıkla rastlanılmaktadır.
# süper lig 2022-2023 sezonunun sonuç tablosundaki ilk 6 takımdan oluşan data frame'i oluşturalım
takim <- c("galatasaray", "fenerbahce", "besiktas", "adana demirspor", "basaksehir", "trabzonspor")
gol <- c(83, 87, 78, 76, 54, 64)
puan <- c(88, 80, 78, 69, 62, 57)
dataFrame1 <- data.frame(takim, gol, puan)
dataFrame1## takim gol puan
## 1 galatasaray 83 88
## 2 fenerbahce 87 80
## 3 besiktas 78 78
## 4 adana demirspor 76 69
## 5 basaksehir 54 62
## 6 trabzonspor 64 57Uzunlukları farklı olan vektörlerle data frame oluşturmaya çalışılırsa, kısa vektör uzun vektör uzunluğunda tekrar edecektir. Uzun vektörün uzunluğu kısa vektörün uzunluğunun bir katı değilse hata mesajı alınacaktır.
x <- 100:103
y <- 10
M <- c(10, 11)
N <- c(4, 5, 6)
# x dört; y ise bir elemanlıdır
data.frame(x, y)## x y
## 1 100 10
## 2 101 10
## 3 102 10
## 4 103 10## Error in data.frame(x, N): arguments imply differing number of rows: 4, 3## Error in data.frame(M, N): arguments imply differing number of rows: 2, 3Data frame’i bir tablo olarak görmek için View() fonksiyonu kullanılır.
View(dataFrame4)4.6.1 R’daki Hazır Veri Setleri
4.6.1.1 iris
iris veri seti, R’daki en meşhur veri setlerinden biridir. Sıklıkla veri görselleştirmenin ya da sınıflamanın gösterilmesi amacıyla kullanılmaktadır. Veriler, İngiliz istatistikçi ve biyolog Ronald Fisher tarafından toplanmıştır. Bazı kaynaklarda bu veri seti Edgar Anderson’un ya da Ronald Fisher’ın iris veri seti şeklinde geçmektedir. Bu veri setinde iris isimli çiçeğin 3 farklı türüne (setosa, versicolor ve virginica) ait dört farklı değişken yer almaktadır. Bu dört değişken bitkilerin yapraklarının (petal ve sepal) genişlik ve uzunluklarını vermektedir. Her türden 50 adet çiçeğin bilgisi veri setinde yer almaktadır. Bu bilgilerden hareketle iris’lerin türü tahmin edilmeye çalışılmaktadır. Bahsi geçen bitki şudur:

Veri setinin ilk 10 satırı şu şekilde incelenebilir:
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa4.6.1.2 mtcars
mtcars, R’da özellikle veri görselleştirme uygulamaları için yaygın olarak kullanılan bir başka veri setidir. Bu veriler 1974 yılı Motor Trend US tarafından derlenmiştir. 32 aracın 11 farklı özelliğini ifade eden değişkenlere sahiptir. Bu değişkenlerin tamamı nümeriktir. Veri setinin ilk 10 satırı şu şekilde incelenebilir:
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 44.6.1.3 penguins
penguins veri seti palmerpenguins paketinin içindeki bir veri setidir. Veriler, bilim insanları tarafından toplanmış ve Antartika’daki Palmer Archipelago’da yaşayan 3 farklı penguenin özelliklerine ilişkin bilgiler içermektedir. Bu 3 penguen türü şunlardır:

Veri setinde bu üç tür penguene ilişkin tür, bulunduğu ada, gaga uzunluğu, gaga derinliği, yüzgeç uzunluğu, kütle, cinsiyet ve yıl değişkenleri bulunmaktadır (Not: gaga uzunluğu olarak kısaltılan bilgi aslında gagasının üst sırtı olarak ifade edilen bölgenin uzunluğudur). Toplam 344 satır ve 8 sütundan oluşmaktadır. Aşağıdaki görselde bu bilgilerden bazıları yer almaktadır.
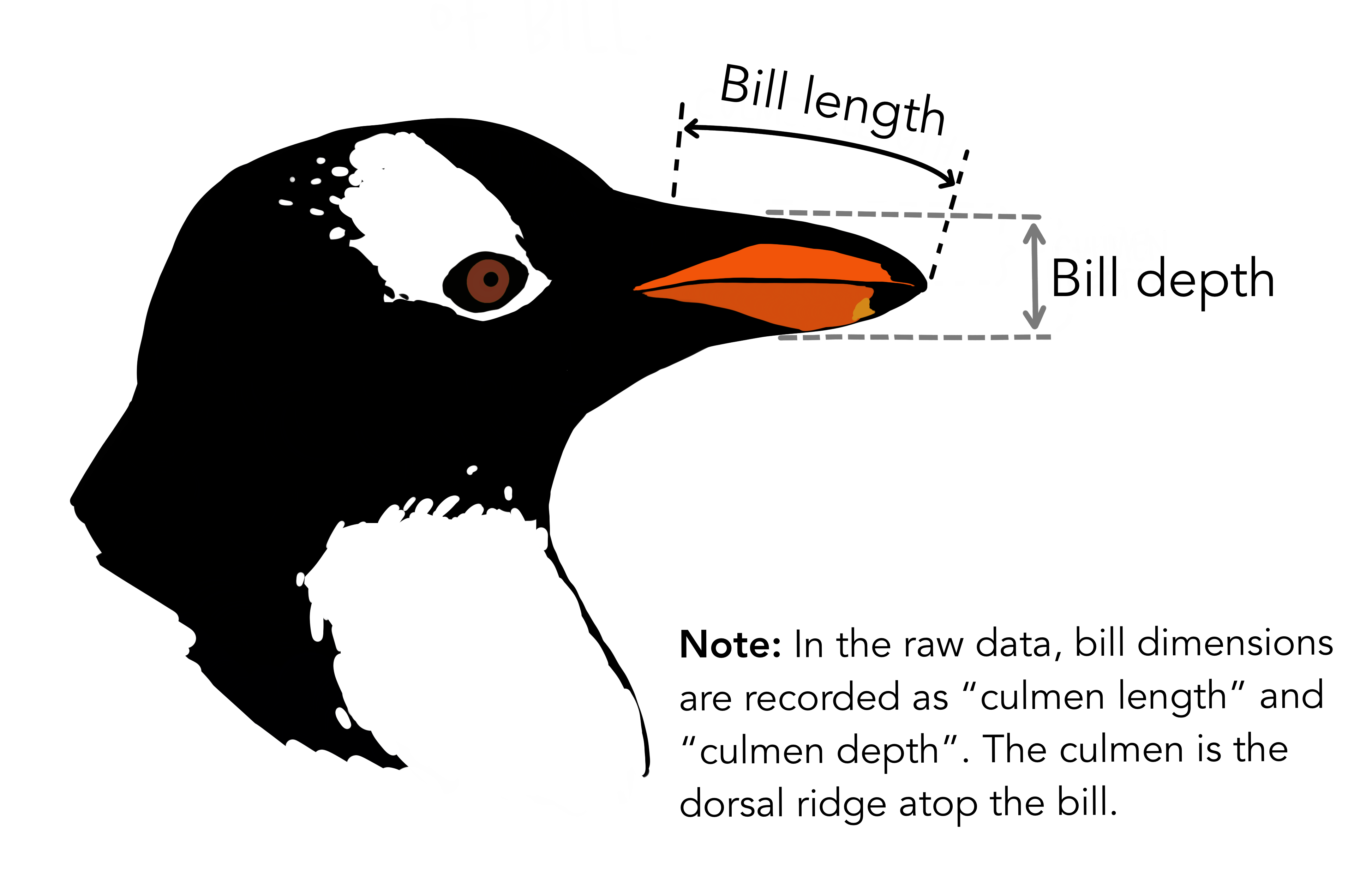
Görüldüğü üzere, eğlenceli bir veri setidir ve genellikle veri görselleştirme uygulamalarında kullanılmaktadır. Bu veri setine ulaşmak için öncelikle install.packages(“palmerpenguins”) komutu ile paket indirilmelidir. Ardından aşağıdaki satır komutları ile veri setinin ilk 10 satırı incelenebilir:
## # A tibble: 10 × 8
## species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
## <fct> <fct> <dbl> <dbl> <int> <int>
## 1 Adelie Torgersen 39.1 18.7 181 3750
## 2 Adelie Torgersen 39.5 17.4 186 3800
## 3 Adelie Torgersen 40.3 18 195 3250
## 4 Adelie Torgersen NA NA NA NA
## 5 Adelie Torgersen 36.7 19.3 193 3450
## 6 Adelie Torgersen 39.3 20.6 190 3650
## 7 Adelie Torgersen 38.9 17.8 181 3625
## 8 Adelie Torgersen 39.2 19.6 195 4675
## 9 Adelie Torgersen 34.1 18.1 193 3475
## 10 Adelie Torgersen 42 20.2 190 4250
## # ℹ 2 more variables: sex <fct>, year <int>4.6.1.4 Titanic
Titanic veri seti R’ın kurulumu ile birlikte gelen veri setlerinden biridir. Daha doğrusu, bu set aslında doğrudan bir data frame değildir. İlk çağrıldığında ‘table’ formatında gelmektedir. Bu formattaki veri seti 4 boyutlu bir çapraz tablo şeklindedir. 4 değişkene ilişkin 2201 gözlem içermektedir. Bazı düzenlemelerin ardından bildiğimiz anlamda veri setine çevrilebilir. Bu veri setinde, tarihte bilinen bir gemi kazasının verisi bulunmaktadır. Düzenleme yapılmasının ardından elde edilen veri setinde ekonomik sınıf, cinsiyet, yaş, hayatta kalıp-kalamama durumu ve frekans sütunları yer alacaktır. Bu veri seti sıklıkla makine öğrenmesi (sınıflandırma temelli algoritmalar) uygulamaları için kullanılmaktadır. Verinin R’a indirilmesi ve gerekli düzenlemelerin yapılması şu şekilde gerçekleşmektedir.
# veri setinin çağırılması
data(Titanic)
# veri setinin istenen formata getirilmesi
library(tibble)
Titanic <- as_tibble(Titanic)Bu işlemlerin ardından Titanic veri seti oluşacaktır. Veri setinin ilk 10 satırı şu şekilde incelenebilir:
## # A tibble: 10 × 5
## Class Sex Age Survived n
## <chr> <chr> <chr> <chr> <dbl>
## 1 1st Male Child No 0
## 2 2nd Male Child No 0
## 3 3rd Male Child No 35
## 4 Crew Male Child No 0
## 5 1st Female Child No 0
## 6 2nd Female Child No 0
## 7 3rd Female Child No 17
## 8 Crew Female Child No 0
## 9 1st Male Adult No 118
## 10 2nd Male Adult No 1544.6.1.5 airquality
airquality, R’da özellikle zaman serileri ve regresyon analizi çalışmalarını örneklendirmek amacıyla kullanılan bir veri setidir. Bu veri setinde New York’un hava kalitesine ilişkin bilgiler bulunmaktadır. 153 satır ve 6 sütundan oluşan veri setinde satırlarda Mayıs 1973’ten Eylül 1973’e kadar ölçümlenen değerler bulunmaktadır. Bu veri setinde kayıp değerler de bulunmaktadır. Bu nedenle kayıp değer analizlerini örneklendirmek amacıyla da kullanılabilirdir. Veri setinin ilk 10 satırı şu şekilde incelenebilir:
## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 104.6.1.6 verbal
verbal veri seti, Vansteelandt’ın (2000) tarafından tez çalışması için toplanmıştır. Bu veri setinin adı ‘Verbal Aggression’dır. Verbal Aggression veri seti “difR” ve “deltaPlotR” paketlerinde hazır olarak sunulmaktadır. Bu veri seti 243 kadın ve 73 erkeğin yanıtlarından (toplam 316 kişi) oluşmaktadır. Veri seti bir matris şeklindedir, 316 satır ve 26 sütundan oluşmaktadır. Sütunlarda 24 adet maddeden alınan puanlar, toplam puanın alındığı ‘Anger’ ve grup değişkeni olan ‘Gender’ yer almaktadır.
Maddeler şu ifadeler ile açıklanmıştır.
Her madde S harfi ile başlamaktadır. S harfinin yanında 1’den 4’e kadar bir ifadeler gelmektedir. Ardından Want (yapmak isterim) ve Do (yaparım) şeklindeki karşılık verme ifadeleri gelmektedir. Son olarak ise olası tepkiler listelenmektedir: Curse, Scold ve Shout.
Örneğin, S2WantCurse maddesinden 1 puan alan bir birey, “bir görevli kendisine hatalı bilgi verdiği için treni kaçırdığında lanetlemek istemektedir.” şeklinde bir yorum yapılabilir. Bu örnek veri seti sıklıkla psikometri alanında yaygın bir şekilde kullanılan DMF analizlerini örneklemek için kullanılabilir. Veri setine ulaşmak için öncelikle install.packages("difR") komutu ile paket indirilmelidir. Ardından veri setinin ilk 5 satırı şu şekilde incelenebilir:
## S1wantCurse S1WantScold S1WantShout S2WantCurse S2WantScold S2WantShout
## 1 0 0 0 0 0 0
## 2 0 0 0 0 0 0
## 3 1 1 1 1 0 1
## 4 1 1 1 1 1 1
## 5 1 0 1 1 0 0
## S3WantCurse S3WantScold S3WantShout S4WantCurse S4WantScold S4WantShout
## 1 0 0 1 1 0 0
## 2 0 0 0 0 0 0
## 3 1 0 0 0 0 0
## 4 1 0 0 0 0 0
## 5 1 0 0 1 0 0
## S1DoCurse S1DoScold S1DoShout S2DoCurse S2DoScold S2DoShout S3DoCurse
## 1 1 0 1 1 0 0 1
## 2 0 0 0 0 0 0 1
## 3 0 1 1 0 0 1 0
## 4 1 1 1 1 1 1 1
## 5 1 1 0 1 0 0 1
## S3DoScold S3DoShout S4DoCurse S4DoScold S4DoShout Anger Gender
## 1 0 0 1 1 1 20 1
## 2 0 0 0 0 0 11 1
## 3 0 0 1 0 0 17 0
## 4 0 0 0 0 0 21 0
## 5 0 0 1 0 0 17 04.7 Veri Yapıları Arasında Dönüşüm
4.7.1 as.list()
## [1] 10 11 12 13 17 20## [[1]]
## [1] 10
##
## [[2]]
## [1] 11
##
## [[3]]
## [1] 12
##
## [[4]]
## [1] 13
##
## [[5]]
## [1] 17
##
## [[6]]
## [1] 20## sayilar sayilar2
## 1 10 1
## 2 11 2
## 3 12 3
## 4 13 4
## 5 17 5
## 6 20 6## $sayilar
## [1] 10 11 12 13 17 20
##
## $sayilar2
## [1] 1 2 3 4 5 64.7.2 as.data.frame()
## [1] 10 11 12 13 17 20## sayilar
## 1 10
## 2 11
## 3 12
## 4 13
## 5 17
## 6 204.7.3 as.matrix()
## [,1]
## [1,] 1
## [2,] 2
## [3,] 3
## [4,] 4
## [5,] 5
## [6,] 6
## [7,] 7
## [8,] 8
## [9,] 9
## [10,] 10
## [11,] 11
## [12,] 12
## [13,] 13
## [14,] 14
## [15,] 15
## [16,] 16
## [17,] 17
## [18,] 18
## [19,] 19
## [20,] 20
## [21,] 21
## [22,] 22
## [23,] 23
## [24,] 24
## [25,] 25
## [26,] 26
## [27,] 27
## [28,] 28
## [29,] 29
## [30,] 30
## [31,] 31
## [32,] 32
## [33,] 33
## [34,] 34
## [35,] 35
## [36,] 36
## [37,] 37
## [38,] 38
## [39,] 39
## [40,] 40
## [41,] 41
## [42,] 42
## [43,] 43
## [44,] 44
## [45,] 45
## [46,] 46
## [47,] 47
## [48,] 48
## [49,] 49
## [50,] 50## sayilar sayilar2
## 1 10 1
## 2 11 2
## 3 12 3
## 4 13 4
## 5 17 5
## 6 20 6## sayilar sayilar2
## [1,] 10 1
## [2,] 11 2
## [3,] 12 3
## [4,] 13 4
## [5,] 17 5
## [6,] 20 64.8 Alıştırmalar
Alıştırma 1
Elemanları “a”, “b” ve “c” olan, 3 elemanlı, ismi ilk3harf olan bir vektör oluşturunuz.
Alıştırma 2
bolum <- c(“egitimde”, “olcme”, “ve”, “degerlendirme”) satır komutunu çalıştırınız. Oluşan bolum isimli
vektörün uzunluğunu (eleman sayısını) hesaplayınız.
Alıştırma 3
not <- c(80, 80, 85, 90, 55, 90, 70, 65) satır komutunu çalıştırınız. not isimli vektördeki değerlerin ortalamasını, standart sapmasını, maksimum ve minimum değerlerini hesaplayınız.
Yanıt İçin Tıklayınız
## [1] 76.875## [1] 12.51784## [1] 90## [1] 55Alıştırma 4
beden <- c("M", "M", "S", "S", "L", "S", "M", "L") satır komutunu çalıştırarak bir vektör oluşturunuz. Ardından bu vektörün S < M < L sıralamasına uyacak şekilde bir faktör olmasını sağlayınız (ordered() fonksiyonundan yararlanınız).
Yanıt İçin Tıklayınız
beden <- c("M", "M", "S", "S", "L", "S", "M", "L")
beden <- ordered(beden, levels = c("S", "M", "L"))
beden## [1] M M S S L S M L
## Levels: S < M < LAlıştırma 5 1’den 20’ye kadar olan sayılar ile 4 satırlı, 5 sütunlu bir matris oluşturunuz. Oluşturulan matriste satır toplamlarını ve sütun ortalamalarını bulunuz.
Yanıt İçin Tıklayınız
## [1] 45 50 55 60## [1] 2.5 6.5 10.5 14.5 18.5Alıştırma 6
Bir adet matris, bir adet karakter vektörü, bir adet de nümerik vektör içeren, 3 elemanlı, adı liste1 olan bir liste oluşturunuz.